Key takeaways
- Catalogued protein sequence clusters: 475,217,233 in UniRef100 (UniProt REST API release 2026_01, accessed April 23, 2026)
- Human protein-coding genes: 19,433 in current GENCODE v49
- Distinct translated human products: 129,801 in current GENCODE v49
- Human Proteome Project reference proteome: 19,435 proteins, with 93.6% confidently detected (2025 HUPO HPP report, published 2026)
- Cell-level molecule counts vary by cell type: about 42 million in a yeast cell, about 10 billion in a typical mammalian cell, and 10 trillion in an NIGMS human-cell estimate
As of April 23, 2026, the cleanest single answer is that UniProt's UniRef100 database contains 475,217,233 protein sequence clusters. That number matters because it describes how much sequence space biology has actually catalogued. But there is no single universal protein count: in humans, you can also count 19,433 protein-coding genes, 129,801 distinct translated products, a 19,435-protein Human Proteome Project reference proteome with 93.6% confident detection, millions of possible proteoforms, or billions to trillions of protein molecules in one cell depending on the cell type and counting method.
Protein counts at a glance
The fastest way to answer "how many proteins are there?" is to choose the counting frame first.
| Question | Best current answer | What is being counted | Source and date |
|---|---|---|---|
| How many catalogued protein sequences are there? | 475,217,233 | UniRef100 exact-sequence clusters | UniProt REST API, accessed April 23, 2026 |
| How many human protein-coding genes are there? | 19,433 | GENCODE protein-coding genes | GENCODE v49 |
| How many distinct translated human products are annotated? | 129,801 | GENCODE distinct translations | GENCODE v49 |
| How much of the human reference proteome has been confidently detected? | 93.6% of 19,435 proteins | HUPO HPP reference proteome with PE1 evidence | 2025 HPP report, published 2026 |
| How many protein molecules are in a yeast cell? | ~42 million | Total protein molecules in an average S. cerevisiae cell | Ho, Baryshnikova, and Brown, 2018 |
| How many protein molecules are in a typical mammalian cell? | ~10 billion | Total protein molecules using cell volume and density estimates | MacCoss et al., 2023 |
| How many protein molecules are in a human cell? | ~10 trillion | NIGMS educational estimate for each human cell | NIGMS, 2025 |
| How many possible 100-amino-acid sequences exist? | 20100 | Theoretical combinations, not observed biology | Combinatoric calculation |
The table combines database counts, annotation counts, experimental-detection counts, cell-abundance estimates, and a theoretical calculation. Those rows should not be averaged or merged into one number.[1]UniRef REST API counts for UniRef100, UniRef90, and UniRef50UniProt · April 23, 2026View source[2]Human release statistics (v49)GENCODEView source[3]The 2025 Report on the Human Proteome from the HUPO Human Proteome ProjectJournal of Proteome Research · 2026View source[5]Sampling the proteome by emerging single-molecule and mass spectrometry methodsNature Methods · 2023View source[7]Proteins by the NumbersNational Institute of General Medical Sciences · 2025View source[8]Unification of protein abundance datasets yields a quantitative Saccharomyces cerevisiae proteomeCell Systems · 2018View source
There is no single protein count
Protein counts range from 19,433 human protein-coding genes to 475,217,233 UniRef100 sequence clusters because different sources count different biological objects.
If you mean known sequences, the relevant number is a database count such as UniRef100. If you mean human gene products, the relevant numbers come from gene annotation sets such as GENCODE and HPP reference lists. If you mean physical molecules inside cells, the number is much larger, because one protein type can exist in thousands to billions of copies.
That is why articles about protein counts often seem to disagree while all being partly correct.
UniRef currently indexes 475.2 million protein sequence clusters
UniProt's UniRef API returned 475,217,233 clusters at 100% identity, 188,848,220 clusters at 90% identity, and 60,315,044 clusters at 50% identity when queried on April 23, 2026.[1]UniRef REST API counts for UniRef100, UniRef90, and UniRef50UniProt · April 23, 2026View source
These are not three different answers to the same question. They are three levels of redundancy reduction. UniRef100 merges exact sequence matches, UniRef90 groups closely related sequences, and UniRef50 compresses the database further into broader protein families.
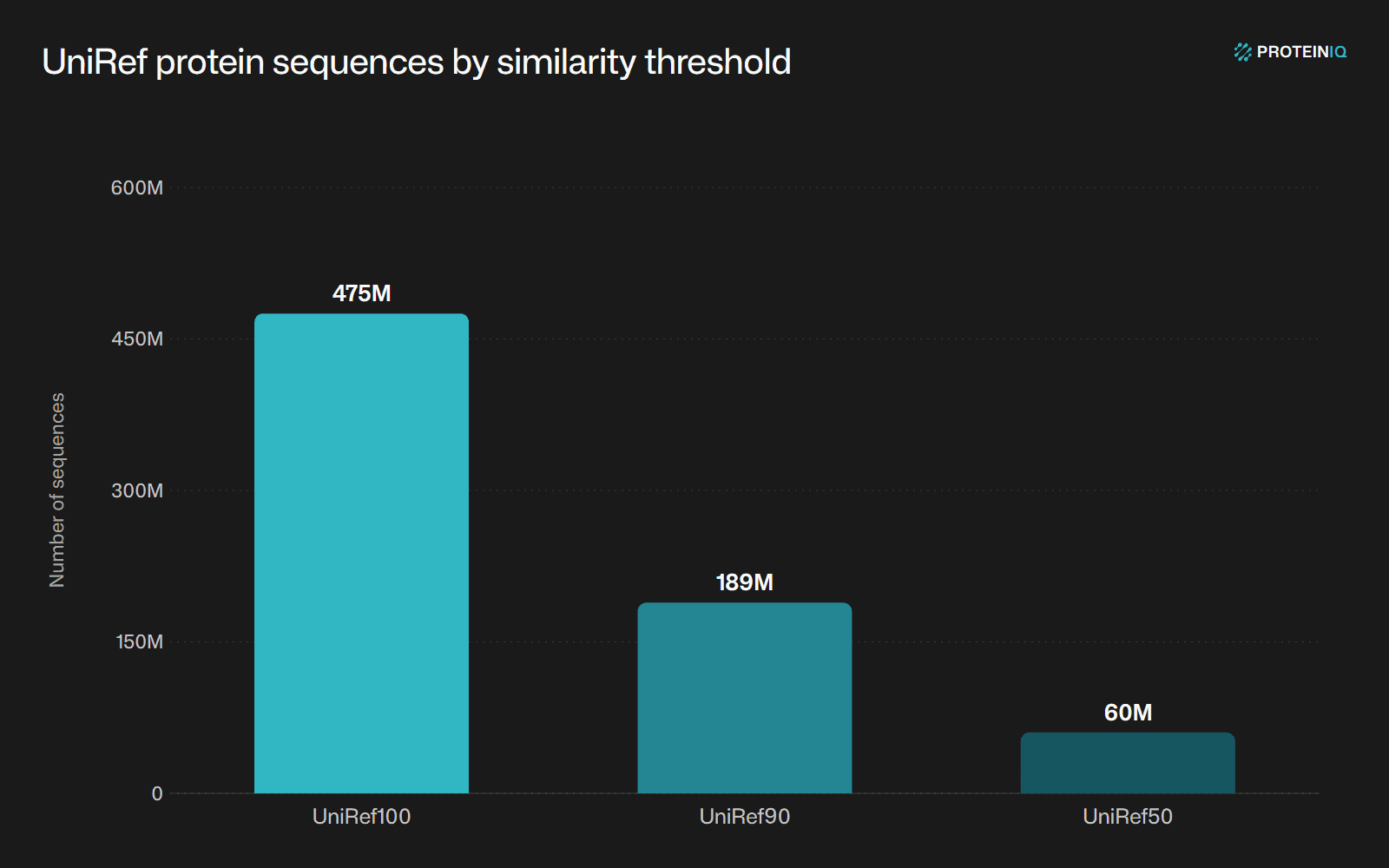
| UniRef dataset | What it counts | Count |
|---|---|---|
| UniRef100 | Exact-sequence clusters | 475,217,233 |
| UniRef90 | Clusters at 90% sequence identity | 188,848,220 |
| UniRef50 | Clusters at 50% sequence identity | 60,315,044 |
Source: UniProt REST API queries for UniRef100, UniRef90, and UniRef50, accessed April 23, 2026. Response headers reported UniProt release 2026_01.[1]UniRef REST API counts for UniRef100, UniRef90, and UniRef50UniProt · April 23, 2026View source
The human proteome is 19,433 genes, 129,801 translated products, and 93.6% confidently detected in HPP
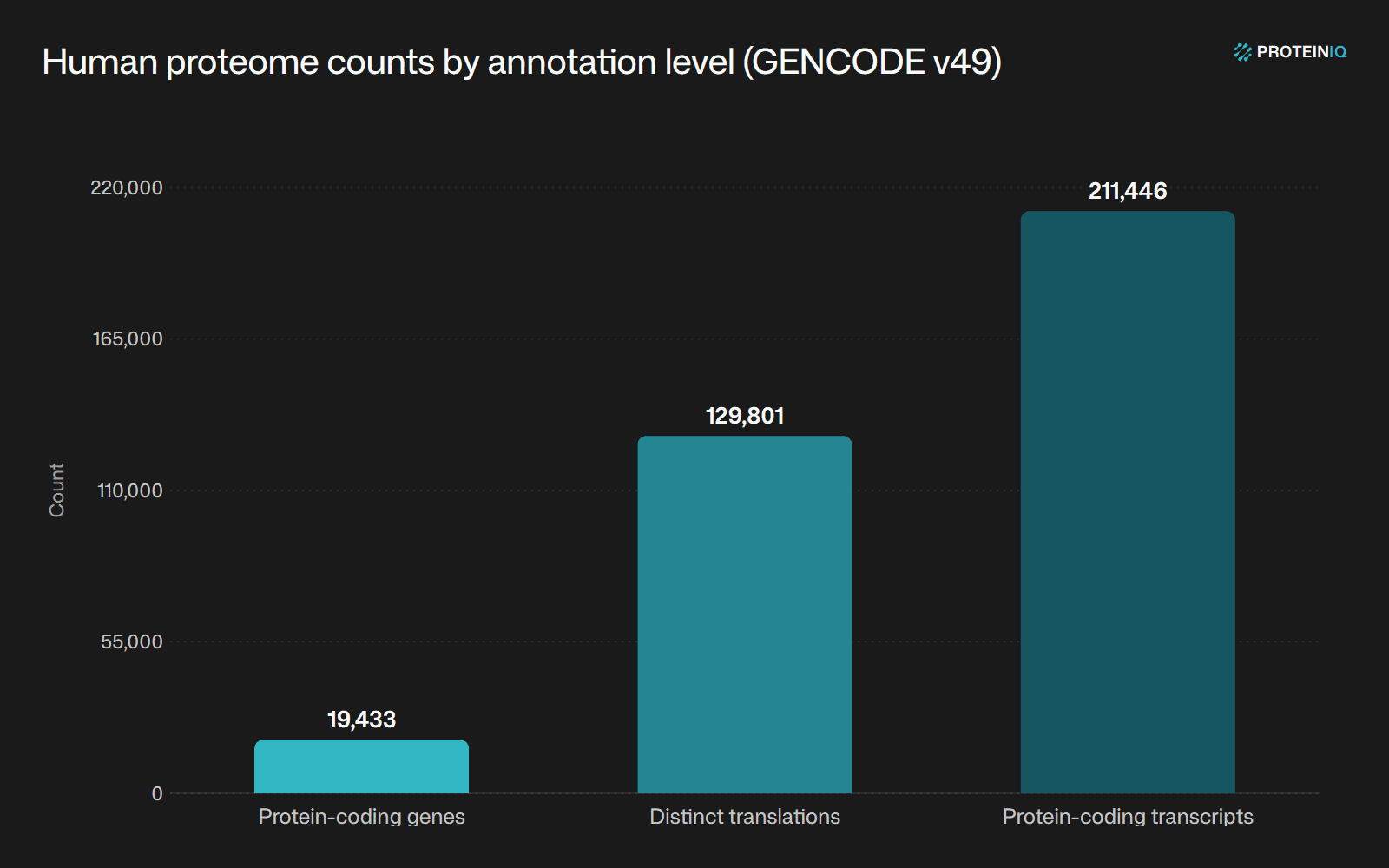
GENCODE v49 lists 19,433 human protein-coding genes, 211,446 protein-coding transcripts, and 129,801 distinct translations.[2]Human release statistics (v49)GENCODEView source
Those are annotation counts: they describe what the current reference gene set says the human genome can encode. The Human Proteome Project asks a different question: how much of the reference proteome has confident evidence of expression?
The 2025 HUPO Human Proteome Project report describes an HPP reference proteome of 19,435 proteins based on GENCODE v48, UniProtKB 2025_03, Human Protein Atlas 24, MassIVE-KB 2023, and PeptideAtlas 2025-01. It reports that 93.6% of that proteome has been detected.[3]The 2025 Report on the Human Proteome from the HUPO Human Proteome ProjectJournal of Proteome Research · 2026View source Human Protein Atlas summarized the same 2025 report as 19,435 protein-coding genes with 94% confident PE1 detection.[4]The 2025 HUPO HPP report on the human proteomeHuman Protein Atlas · 2026View source
| Human proteome level | Count | What it means |
|---|---|---|
| Protein-coding genes | 19,433 | Genes annotated as protein-coding in GENCODE v49 |
| Protein-coding transcripts | 211,446 | Transcript isoforms annotated as protein-coding |
| Distinct translations | 129,801 | Distinct translated protein products in GENCODE v49 |
| HPP reference proteome | 19,435 proteins | 2025 HUPO HPP target list based on GENCODE v48 plus integrated protein resources |
| Confidently detected HPP proteins | 93.6% | Share of the 2025 HPP reference proteome detected with confident expression evidence |
This separation matters. A gene count is not a protein count, an annotated translation count is not the same thing as a protein that has been directly observed in experiments, and the current GENCODE v49 gene count does not have to match the 2025 HPP target list exactly because the HPP report used GENCODE v48 plus additional protein resources.
Proteins, isoforms, and proteoforms are different counts
A protein-coding gene, a translated product, and a proteoform are three different biological objects.
An isoform is usually a sequence-level variant produced by mechanisms such as alternative splicing. A proteoform is broader: it includes the different molecular forms of a protein produced from genetic variation, splicing, RNA editing, cleavage, and post-translational modifications such as phosphorylation or glycosylation.[9]How many human proteoforms are there?Nature Chemical Biology · 2018View source
That is why the human count can be 19,433 protein-coding genes, 129,801 annotated distinct translations, and still have far more molecular diversity inside cells. Aebersold and colleagues argued that better estimates of human proteoform diversity are needed because the number depends on how sequence variants and modification combinations are defined and measured.[9]How many human proteoforms are there?Nature Chemical Biology · 2018View source
For citation purposes, avoid writing that humans "have 20,000 proteins" unless you mean protein-coding genes or a reference proteome. If you mean molecular forms in cells, use proteoforms and state that the exact count is not fixed.
A typical mammalian cell contains about 10 billion protein molecules
A 2023 review on protein counting and single-molecule proteomics says a typical mammalian cell of roughly 3,000 um3 contains about 10,000,000,000 protein molecules, with a typical density of about 3 million protein molecules per cubic micrometer.[5]Sampling the proteome by emerging single-molecule and mass spectrometry methodsNature Methods · 2023View source
That is a molecule count, not a count of unique protein types. Deep mass-spectrometry studies can identify around 10,411 protein groups in a 30-minute human cell-line proteomics run, which shows the gap between counting protein copies and counting protein species.[6]The One Hour Human ProteomePubMed · 2024View source
For a practical mental model:
| Cell-level measure | Typical value | Source |
|---|---|---|
| Total protein molecules in an average yeast cell | ~42 million | 2018 Cell Systems |
| Total protein molecules in a mammalian cell | ~10 billion | 2023 review |
| Total protein molecules in a human cell | ~10 trillion | 2025 NIGMS estimate |
| Protein density | ~3 million molecules per um^3 | 2023 review |
| Protein groups identified in a fast deep human proteome run | 10,411 | 2024 proteomics study |
Why cell-level protein counts disagree
Cell-level protein counts disagree because they mix different organisms, cell sizes, and measurement strategies.
The 42 million number comes from an average budding yeast cell. Ho, Baryshnikova, and Brown unified 21 yeast protein-abundance datasets and estimated molecule counts for the Saccharomyces cerevisiae proteome.[8]Unification of protein abundance datasets yields a quantitative Saccharomyces cerevisiae proteomeCell Systems · 2018View source That is a strong estimate for yeast, not a universal human-cell number.
The 10 billion number comes from a typical mammalian-cell calculation that combines cell volume with protein-molecule density.[5]Sampling the proteome by emerging single-molecule and mass spectrometry methodsNature Methods · 2023View source The 10 trillion number appears in a 2025 NIGMS educational "by the numbers" article as an estimate for each human cell.[7]Proteins by the NumbersNational Institute of General Medical Sciences · 2025View source Those estimates can differ by orders of magnitude because "a human cell" is not one standard object: red blood cells, neurons, epithelial cells, oocytes, and cultured cell lines differ in size, protein concentration, and biological state.
Use the organism and cell type whenever possible. "A yeast cell contains about 42 million protein molecules" is more precise than "a cell contains 42 million proteins." "A typical mammalian cell contains about 10 billion protein molecules" is more precise than "the human body has 10 billion proteins."
Protein sequence space is far larger than biology has sampled
For a protein just 100 amino acids long, the number of possible sequences is 20100 because each position can hold one of 20 standard amino acids.
That theoretical space is so large that the 475.2 million catalogued UniRef100 clusters represent only a tiny, biologically explored corner of what chemistry allows. This is one reason protein engineering and protein design still have so much open search space.
Methodology
This article uses six different counting frames, and they should not be merged into a single headline number.
| Counting frame | Method |
|---|---|
| Known sequence clusters | Live UniProt UniRef REST API queries run on April 23, 2026. The counts are read from the X-Total-Results response header. |
| Human annotated genes, transcripts, and translations | Current GENCODE human statistics, release v49.[2]Human release statistics (v49)GENCODEView source |
| Human protein detection status | The 2025 HUPO Human Proteome Project report. Its HPP reference proteome count is not substituted for the current GENCODE v49 gene count because it was built from GENCODE v48 plus integrated proteomics resources.[3]The 2025 Report on the Human Proteome from the HUPO Human Proteome ProjectJournal of Proteome Research · 2026View source |
| Typical mammalian-cell molecules | A review that summarizes cell volume and molecule-density estimates. These are molecule counts, not unique protein-type counts.[5]Sampling the proteome by emerging single-molecule and mass spectrometry methodsNature Methods · 2023View source |
| Yeast and NIGMS cell-level molecule counts | Yeast counts come from the 2018 Cell Systems abundance unification study, while the NIGMS human-cell number is treated as an educational estimate rather than a single-cell-type measurement.[7]Proteins by the NumbersNational Institute of General Medical Sciences · 2025View source[8]Unification of protein abundance datasets yields a quantitative Saccharomyces cerevisiae proteomeCell Systems · 2018View source |
| Proteoforms | The 2018 Nature Chemical Biology perspective, which emphasizes that the number of human proteoforms depends on how sequence variation, splicing, and post-translational modifications are defined and measured.[9]How many human proteoforms are there?Nature Chemical Biology · 2018View source |
The theoretical 20100 sequence-space figure is a simple combinatoric calculation, not a database count.
How to cite this page
Use this article as a dated statistics source only with the access date, because UniRef, GENCODE, UniProtKB, and HPP counts change across releases.
ProteinIQ. "How many proteins are there?" Updated June 2, 2026. Accessed [your access date]. https://proteiniq.io/guides/number-of-proteins
Number of proteins FAQs
How many proteins are there in total?
The best current total for catalogued protein sequence space is 475,217,233 UniRef100 exact-sequence clusters, accessed through the UniProt REST API on April 23, 2026. This is not the total number of possible proteins, because possible amino-acid sequences are vastly larger than known biological sequences.
How many proteins are there in the human body?
There is no single human-body count. Humans have 19,433 protein-coding genes in GENCODE v49, 129,801 distinct annotated translations, a 19,435-protein HPP reference proteome with 93.6% confident detection, and many more proteoforms once molecular modifications are counted.
How many proteins are in one cell?
It depends on the cell. A yeast cell contains about 42 million protein molecules, a typical mammalian cell is often estimated at about 10 billion, and NIGMS gives 10 trillion as an educational estimate for a human cell. These are molecule counts, not counts of unique protein types.
How many types of proteins are there?
If "types" means broad biological functions, proteins are often grouped as enzymes, structural proteins, transporters, receptors, signaling proteins, antibodies, and motor proteins. If "types" means distinct human gene products, current annotation gives 129,801 distinct translated products in GENCODE v49.
How many amino acids are in proteins?
Most proteins are built from 20 standard amino acids. Protein length varies widely, from very small peptides and miniproteins to giant proteins such as titin. The number of possible sequences grows exponentially: a 100-amino-acid chain has 20100 possible standard-amino-acid combinations.
Why are there more proteins than protein-coding genes?
One gene can produce multiple protein products through alternative splicing, alternative start sites, sequence variation, cleavage, and post-translational modification. That is why 19,433 human protein-coding genes can correspond to 129,801 annotated translations and a much larger proteoform space.
Sources▼
- UniRef REST API counts for UniRef100, UniRef90, and UniRef50 UniProt · April 23, 2026. https://rest.uniprot.org/uniref/search?size=1&query=identity%3A1.0
- Human release statistics (v49) GENCODE. https://www.gencodegenes.org/human/stats.html
- The 2025 Report on the Human Proteome from the HUPO Human Proteome Project Journal of Proteome Research · 2026. https://pubs.acs.org/doi/full/10.1021/acs.jproteome.5c00759
- The 2025 HUPO HPP report on the human proteome Human Protein Atlas · 2026. https://www.proteinatlas.org/news/2026-02-20/the-2025-hupo-hpp-report-on-the-human-proteome
- Sampling the proteome by emerging single-molecule and mass spectrometry methods Nature Methods · 2023. https://www.nature.com/articles/s41592-023-01802-5
- The One Hour Human Proteome PubMed · 2024. https://pubmed.ncbi.nlm.nih.gov/38579929/
- Proteins by the Numbers National Institute of General Medical Sciences · 2025. https://nigms.nih.gov/biobeat/2025/01/proteins-by-the-numbers/
- Unification of protein abundance datasets yields a quantitative Saccharomyces cerevisiae proteome Cell Systems · 2018. https://www.cell.com/cell-systems/fulltext/S2405-4712(17)30546-X
- How many human proteoforms are there? Nature Chemical Biology · 2018. https://pmc.ncbi.nlm.nih.gov/articles/PMC5837046/