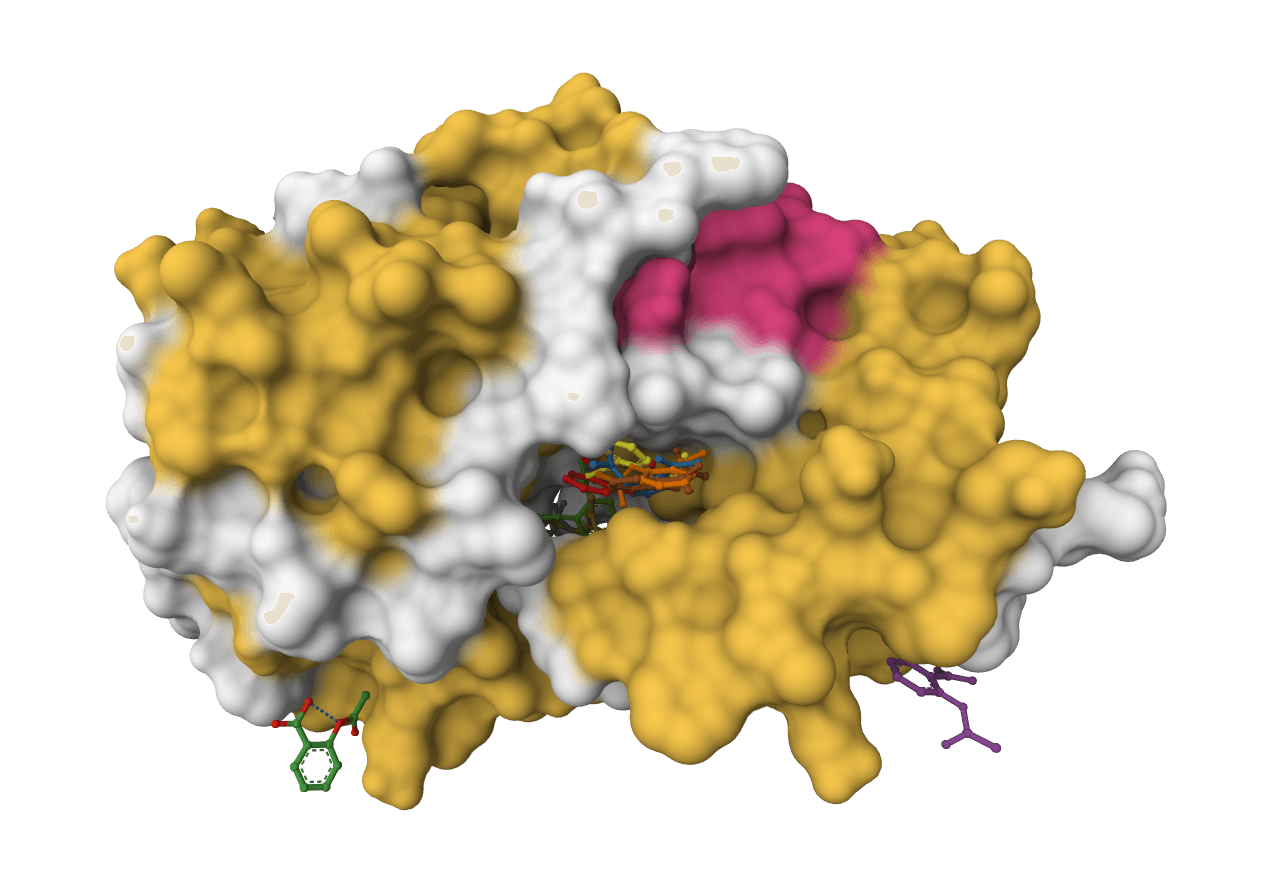
What is DiffDock-L?
DiffDock-L is the latest version of the molecular docking tool developed at MIT that uses diffusion models to predict how small molecule ligands bind to protein targets. For a related surface-aware diffusion docking approach, compare with SurfDock. It treats molecular docking as a generative modeling task rather than traditional optimization, using the same technology that powers image generators like DALL-E and Stable Diffusion.
Building upon the original DiffDock published at ICLR 2023, DiffDock-L (released at ICLR 2024) achieves significantly better accuracy and generalization to novel protein targets.
DiffDock-L vs. DiffDock
DiffDock-L introduced several enhancements over the original DiffDock:
Enhanced accuracy: DiffDock-L achieves 43% success rate for ligand RMSD <2Å compared to the original DiffDock's 38%. On the DockGen benchmark designed to test generalization across protein domains, success rate improved from 10% to 24%.
Better generalization: The model uses ECOD (Evolutionary Classification of protein Domains) structure-based cluster sampling during training to ensure better performance on proteins with novel binding pocket architectures.
Larger model & more training data: DiffDock-L scales from 4M to 30M parameters and benefits from increased training data and novel synthetic data generation (extracting side chains from protein structures as ligands).
Confidence bootstrapping: A novel self-training scheme where the diffusion model and confidence model work together to fine-tune on unseen protein domains without structural data.
Optimized output: By default, DiffDock-L outputs 10 high-quality predictions compared to the previous 40, reducing computation time by approximately 2x while maintaining superior accuracy.
How does DiffDock-L work?
Unlike traditional docking methods that use physics-based scoring functions and optimization algorithms, DiffDock-L applies diffusion models to molecular docking. The key innovation is treating docking as a generative modeling task over a non-Euclidean manifold rather than an optimization problem.
Diffusion process on SE(3) manifold
DiffDock-L defines a diffusion process over the degrees of freedom involved in docking: the ligand's position relative to the protein (translation), its orientation in the binding pocket (rotation), and the torsion angles describing its conformation. This maps to the SE(3) manifold—the Special Euclidean group in 3D space that represents all possible rigid body transformations.
The model starts with a random ligand pose and iteratively denoises it through learned reverse diffusion steps to converge on plausible binding poses. Unlike traditional methods that optimize a single pose, this generative approach naturally produces diverse binding modes.
Graph representation
Protein and ligand structures are represented as heterogeneous geometric graphs. Ligand atoms and protein residues serve as nodes, with residues receiving initial features from language model embeddings trained on protein sequences.
Nodes are sparsely connected based on distance cutoffs that depend on node types and diffusion timestep, allowing efficient message passing while capturing relevant interactions.
Embedding message-passing layers
DiffDock-L adds embedding message-passing layers that independently process protein and ligand structures before cross-attention. Unlike DiffDock's purely cross-attentional layers, this allows increased architectural depth with minimal runtime overhead.
Under the rigid protein assumption, protein embeddings are computed once and cached across all diffusion steps and samples, providing efficiency gains.
SE(3) equivariant neural networks
The model uses geometric deep learning with SE(3) equivariance—rotations and translations of the input don't change the predicted binding physics, only the coordinate frame. This physical symmetry is encoded through specialized graph neural networks that process geometric information while respecting 3D symmetries, improving generalization and data efficiency.
Confidence model
For each generated pose, DiffDock-L predicts a confidence score estimating the likelihood that the pose has RMSD <2Å to the true binding mode. This confidence model is trained jointly with the diffusion model and enables automatic ranking of generated poses without requiring external scoring functions.
Input requirements
DiffDock-L requires two inputs:
- Protein structure: A PDB file or PDB ID from RCSB PDB database. The protein should be prepared (protonated, cleaned) for best results—use PDB Fixer to prepare it.
- Ligand: SMILES string, SDF, MOL2, or MOL file format.
Docking parameters
Number of poses: How many binding poses to generate. We recommend starting with 10-20 poses for general use. Increase to 30-40 if exploring diverse binding modes—more poses increase computation time proportionally.
Inference steps: Number of diffusion denoising steps. The model was trained with 20 steps. Research suggests 15 is optimal for speed/accuracy balance.
Actual steps: Number of steps actually executed (usually inference_steps - 2). This is an advanced parameter for optimization.
No final step noise: Removes noise from the final denoising step for more stable and deterministic predictions. We recommend keeping this enabled.
Save reverse-diffusion visualization: Writes an additional PDB trajectory for each ranked pose showing the reverse diffusion process. This is useful for debugging and qualitative inspection, but it increases output size.
Understanding the results
DiffDock-L generates multiple binding poses ranked by confidence.
Rank
Poses are sorted by confidence score, with Rank 1 being the most confident prediction.
Confidence score
A model-predicted score indicating confidence in the binding pose. Higher (less negative) scores indicate higher confidence:
- Score > -1.5: High confidence
- Score -1.5 to -2.5: Moderate confidence
- Score < -2.5: Lower confidence
The confidence model estimates the probability that a pose has RMSD <2Å to the true binding mode.
Multiple poses
We recommend examining multiple top-ranked poses:
- Different poses may represent alternative binding modes
- The highest-ranked pose isn't always correct
- Ensemble analysis provides more robust predictions
Output files
DiffDock-L returns each ranked ligand pose as an SDF file, which preserves small-molecule bond orders and atom typing more faithfully than ligand-only PDB exports.
If reverse-diffusion visualization is enabled, DiffDock-L also returns a PDB trajectory for each ranked pose showing the denoising path used to reach the final docking configuration.
Best practices
Protein preparation
Clean structures yield better results:
- Remove water molecules unless they're critical for binding
- Add missing hydrogens and residues
- Ensure proper protonation states at physiological pH
- Use PDB Fixer for automated preparation
Result validation
- Examine top 3-5 ranked poses, not just the top one
- Check for reasonable protein-ligand interactions (H-bonds, hydrophobic contacts)
- Validate critical predictions with molecular dynamics or experimental methods
Limitations
DiffDock-L has known limitations that may affect certain use cases:
- Does not account for protein flexibility (rigid receptor assumption)
- Performance may vary for large or macrocyclic ligands
- Metalloprotein binding requires special consideration
- Trained primarily on x-ray structures; performance on computationally folded structures is reduced but still superior to traditional methods
Comparison to traditional docking
Advantages of DiffDock-L
- Superior accuracy: 43% success rate (RMSD <2Å) versus 23% for traditional methods on PDBBind
- Better handling of flexible ligands: Generative approach naturally models conformational flexibility
- No manual parameter tuning: Works out-of-the-box without exhaustive search parameters
- Diverse poses: Diffusion sampling generates multiple binding modes automatically
- Confidence estimates: Built-in confidence model for pose ranking
Traditional methods (AutoDock Vina, GNINA)
- Faster computation: Optimization-based approaches can be quicker for simple systems
- More interpretable: Physics-based scoring functions provide mechanistic insights
- Established validation: Decades of validation in drug discovery pipelines
- Specialized cases: Better support for metals, covalent binding, and specific constraints
For most drug discovery applications, DiffDock-L provides the best balance of accuracy and ease of use.
Related tools
DynamicBind
DynamicBind is an AI-powered protein-ligand binding prediction tool that recovers ligand-induced conformational changes from unbound protein structures. It predicts both ligand binding poses and protein conformational changes.
SigmaDock
SigmaDock is a fragment-based molecular docking tool using SE(3) equivariant diffusion models to predict how small molecule ligands bind to protein targets. Presented at ICLR 2026, it generates multiple binding poses with Vinardo scoring.
FlowDock
FlowDock predicts protein-ligand complex structures and binding-affinity scores using geometric flow matching.
SurfDock
SurfDock is a surface-informed diffusion generative model for protein-ligand docking, published in Nature Methods 2024. It leverages protein surface geometry to guide a diffusion process for reliable and accurate protein-ligand complex prediction.
AutoDock-GPU
GPU-accelerated molecular docking using the AutoDock4 force field. Up to 56x faster than serial AutoDock via CUDA parallelization of the Lamarckian Genetic Algorithm.
AutoDock Vina
AutoDock Vina is a widely-used molecular docking tool that predicts protein-ligand binding modes using physics-based force fields. Fast, reliable, and the gold standard for structure-based drug discovery.
GNINA
GNINA is a molecular docking tool that combines traditional physics-based docking with deep learning CNN scoring for protein-small-molecule complexes. It provides accurate binding predictions with confidence scores, optimized for high-throughput virtual screening.
PandaDock
Open-source molecular docking platform using physics-based scoring functions. CPU-optimized algorithms achieve sub-angstrom accuracy (0.014A RMSD) without GPU requirements.
SMINA
SMINA is a fork of AutoDock Vina with enhanced scoring functions, custom scoring support, and 10-20x faster minimization. Ideal for scoring function development, pose refinement, and high-performance docking workflows.
TEMPL Pipeline
TEMPL Pipeline predicts protein-ligand poses by finding similar protein templates, aligning template ligands, generating constrained conformers, and ranking poses with shape and pharmacophore scores.