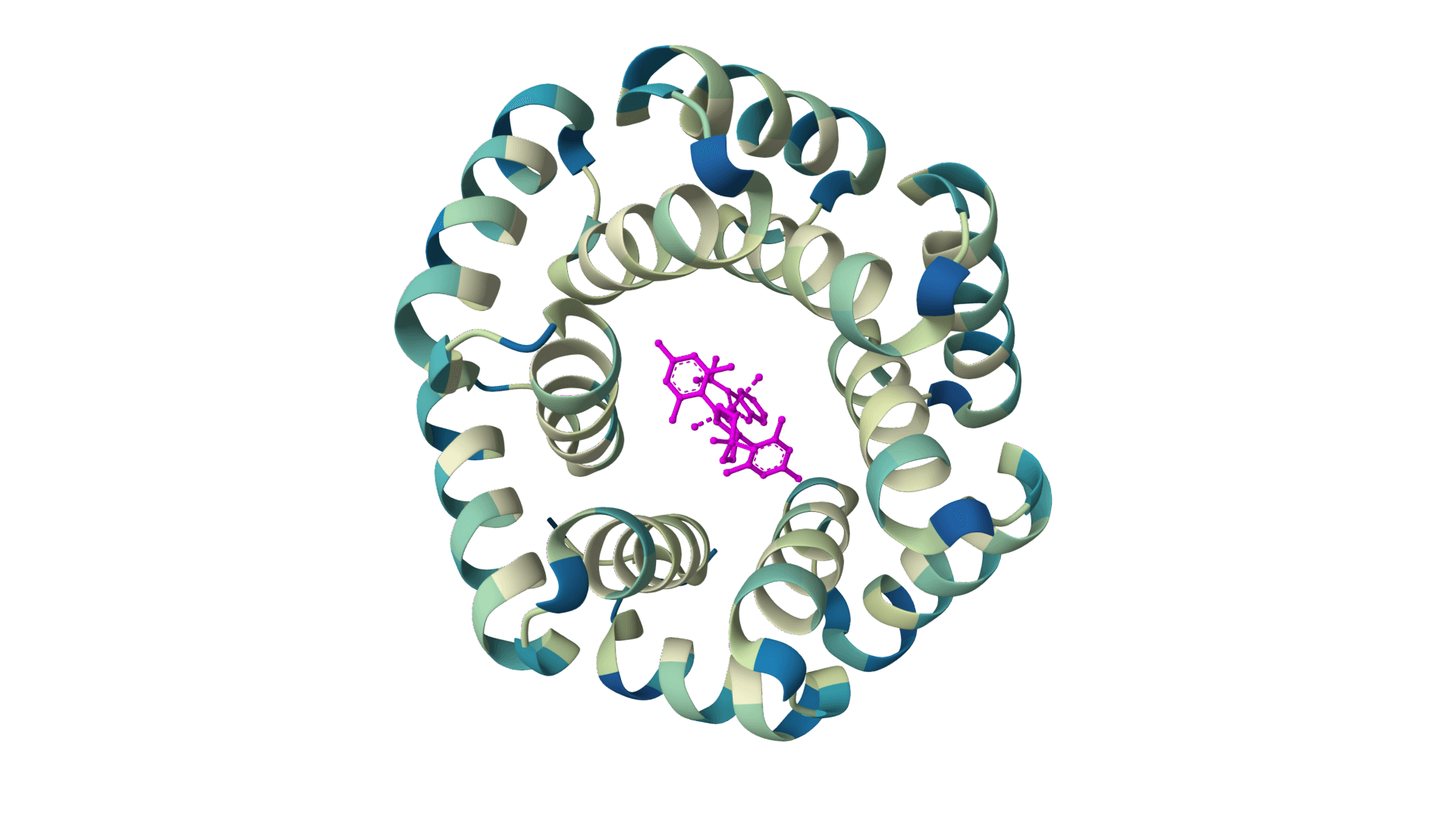
What is LigandMPNN?
LigandMPNN is an inverse folding model that designs protein sequences while accounting for non-protein atoms—ligands, metals, nucleotides, and cofactors. Standard inverse folding methods like ProteinMPNN only see the protein backbone, which limits their accuracy at binding sites where interactions with small molecules matter most. LigandMPNN solves this by incorporating atomic context from heteroatoms during sequence prediction.
The improvement is substantial. At small molecule binding sites, LigandMPNN achieves 63.3% sequence recovery compared to 50.5% for ProteinMPNN. Metal coordination sites show an even larger gap: 77.5% versus 36.0%. These gains translate to better experimental success rates—over 100 designs have been validated, with some showing 100-fold affinity improvements over conventional methods.
Developed by Dauparas, Lee, and colleagues at the Institute for Protein Design, LigandMPNN was published in Nature Methods (2025).
How does LigandMPNN work?
LigandMPNN extends ProteinMPNN's graph neural network by processing three interconnected graphs instead of one: a protein-only graph (residues as nodes), a ligand-only graph (heteroatoms as nodes), and a protein-ligand graph that captures residue-atom interactions. This architecture allows the model to learn chemical element identities and geometric constraints at binding interfaces.
The model consists of a protein backbone encoder (3 layers), a protein-ligand encoder (2 layers), and an autoregressive decoder that generates both amino acid sequences and sidechain torsion angles. Training used 8–16 context atoms per residue and added 0.1 Å Gaussian noise to coordinates, improving generalization to novel structures.
How to use LigandMPNN online
ProteinIQ hosts LigandMPNN on cloud GPU infrastructure, eliminating the need to install Python dependencies or configure the model locally.
Inputs
| Input | Description |
|---|---|
Protein | PDB file (up to 50 MB), .ent, .cif, or RCSB PDB ID. Ligand atoms are read from HETATM records already present in the structure—no separate ligand file is needed for structures fetched from RCSB. |
Ligand | Optional. SMILES string, SDF/MOL file, or PubChem CID for reference. LigandMPNN reads atomic context directly from HETATM records in the PDB; the ligand input is informational context only. |
Core settings
| Setting | Description |
|---|---|
Number of sequences | How many sequence variants to generate (1–48, default 8). More sequences give better coverage of sequence space but increase runtime. Start with 8–10 for initial testing; use 20–40 for comprehensive exploration. |
Sampling temperature | Controls diversity (0.05–1.0, default 0.1). Lower values produce conservative designs with high recovery; higher values explore more diverse solutions. For metal sites, 0.1–0.15 is recommended. |
Use atom context | Include ligands, metals, and nucleotides during design (default on). Disabling this makes LigandMPNN behave like ProteinMPNN—only useful as a control. |
Use side chain context | Include fixed residue sidechains as geometric constraints. Enable when catalytic or binding residues are fixed and their geometry should influence neighboring positions. |
Random seed | Integer for reproducible results (0–99999, default 111). Same seed and settings produce identical output. |
Design options
| Setting | Description |
|---|---|
Chains to design | Specify which chains to redesign (e.g., A,B); all others stay fixed. Simpler than listing every fixed residue for multi-chain proteins. |
Homo-oligomer | Enable symmetric design for proteins with identical chains. All chains receive the same sequence. |
Fixed positions | Residues to keep unchanged. Format: A15, A1-10, B1-20, or C for an entire chain. Comma-separate multiple entries. |
Redesigned positions | Inverse of fixed positions—specify what to design and fix everything else. Cannot be used simultaneously with Fixed positions. |
Parse chains only | Parse only specified chains from the PDB, ignoring all others. Useful for large assemblies where only a subset of chains is relevant. |
Scoring cutoff (Å) | Distance cutoff for selecting residues scored with ligand context (default 8.0 Å). Decrease to focus design on residues very close to the ligand; increase for broader context. |
Include zero-occupancy atoms | Include atoms with zero occupancy from crystal structures, which indicate partially occupied or disordered positions. Off by default. |
Exclude amino acids | Globally exclude one or more amino acids from all designed positions. Enter one-letter codes without separators (e.g., CW to exclude cysteine and tryptophan). |
Amino acid biases | Adjust sampling frequency per amino acid. Positive values (0 to +5) increase likelihood; negative values (down to −25) decrease it. Setting a value of −25 effectively excludes that amino acid entirely. |
Output
Each designed sequence includes:
| Column | Description |
|---|---|
Sequence ID | Unique identifier for the design (seq_1, seq_2, …) |
Sequence | Designed amino acid sequence, with chains separated by / in FASTA output |
Length | Total residue count across all designed chains |
Overall confidence | Model confidence (0–1). Computed as over residues. Higher values indicate stronger sequence-structure compatibility. |
Ligand confidence | Confidence specifically at residues within the scoring cutoff distance of ligand atoms. Distinct from overall confidence; provides a focused view of binding site quality. |
Seq recovery | Fraction of positions matching the input sequence |
Mutation count | Number of positions that differ from the input |
Identity % | Percent identity to the input sequence |
Results are available as FASTA, CSV, JSON, and backbone PDB files.
LigandMPNN vs ProteinMPNN
| Feature | ProteinMPNN | LigandMPNN |
|---|---|---|
| Input context | Protein backbone only | Protein + ligands, metals, nucleotides |
| Binding site recovery | 50.5% | 63.3% |
| Metal coordination recovery | 36.0% | 77.5% |
| Nucleotide binding recovery | 35.2% | 50.5% |
| Model size | 1.66M parameters | 2.62M parameters |
| Architecture | Single protein graph | Three-graph (protein, ligand, protein-ligand) |
| Sidechain prediction | No | Yes (torsion angles) |
| Speed | Faster | ~2× slower |
| Credit cost | 25 | 50 |
When to use each
Use ProteinMPNN for general protein design where no ligands or cofactors are involved—de novo protein scaffolds, antibody frameworks away from CDRs, or soluble protein cores.
Use LigandMPNN whenever the design involves binding sites: enzyme active sites, cofactor-binding pockets (NAD, FAD, heme), metal coordination spheres, or nucleic acid interfaces. The sequence recovery improvements at these sites translate directly to higher experimental success rates.
Use RFdiffusion 2 before LigandMPNN when the backbone itself needs to be generated rather than only resequenced.
Limitations
- Ligand context comes from HETATM records already present in the PDB. Structures without these records default to ProteinMPNN-like behavior regardless of whether a separate ligand is provided.
- Computational cost is roughly double that of ProteinMPNN due to the additional encoder layers.
- Designed sequences require experimental validation—high confidence scores improve success rates but do not guarantee function.
Related tools
HyperMPNN
Design thermostable protein sequences using ProteinMPNN trained on hyperthermophilic organism structures. Generates sequences optimized for improved thermal stability without requiring ligands or additional context.
ProteinMPNN
Design protein sequences for given backbone structures using deep learning. Fast and accurate inverse folding with state-of-the-art sequence recovery (52.4%).
SolubleMPNN
Specialized model for soluble protein sequence design. Trained exclusively on soluble proteins for optimized performance on cytoplasmic and extracellular proteins.
IgDesign
Design antibody CDR sequences via inverse folding. Generates complementarity-determining region (CDR) sequences for antibodies targeting therapeutic antigens using deep learning. Optimizes CDR loops (HCDR1, HCDR2, HCDR3) based on antibody-antigen complex structures.
AntiFold
Inverse folding for antibody variable domains and nanobodies. Predicts amino acid sequences compatible with antibody structures using IMGT numbering while preserving native AntiFold chain handling and structural constraints.
ESM-IF1
Inverse folding with ESM-IF1. Design protein sequences for given 3D backbone structures using a geometric deep learning model. Generate multiple sequence variants optimized for your target structure.

ProFam
ProFam-1 is a protein family language model for family-conditioned sequence generation. Provide a protein family FASTA/MSA and generate new sequences with model likelihood scores for downstream ranking and screening.
RFdiffusion 2
RFdiffusion2 is an atom-level enzyme active site scaffolding tool that generates protein scaffolds around your input motif. REQUIRES an input PDB structure containing the active site residues to scaffold. For ligand-aware design, ligands must be embedded in the input PDB as HETATM records.
RFdiffusion3
All-atom generative diffusion model for protein design with complex constraints. Design binders, enzymes, and symmetric protein assemblies.
PepMLM
Design linear peptide binders for target proteins using a target sequence-conditioned masked language model. PepMLM generates peptide sequences optimized to bind specific protein targets based on ESM-2 protein language modeling.