Enzyme engineering workflows
Engineer enzymes readyfor functional testing.
Annotate enzymes, inspect substrate context, predict activity signals, score mutations, and compare structure-guided outputs in one connected workflow.
Result generated with Chai-1
Capabilities
Enzyme engineering models
DLKcat
DLKcat predicts enzyme turnover numbers (kcat values) from protein sequences and substrate structures using deep learning. Combines CNN and GNN architectures for accurate kinetic parameter prediction.
CleaveNet
Official CleaveNet tool for matrix metalloproteinase cleavage prediction and peptide generation. Predict cleavage z-scores plus uncertainty across 18 MMP variants, evaluate against truth z-scores, or generate candidate peptides unconditionally or from MMP z-score profiles.
ThermoMPNN
Predict protein thermostability changes (ΔΔG) for point mutations using a graph neural network. Enables computational saturation mutagenesis screening to identify stabilizing mutations.
ProteinMPNN
Design protein sequences for given backbone structures using deep learning. Fast and accurate inverse folding with state-of-the-art sequence recovery (52.4%).
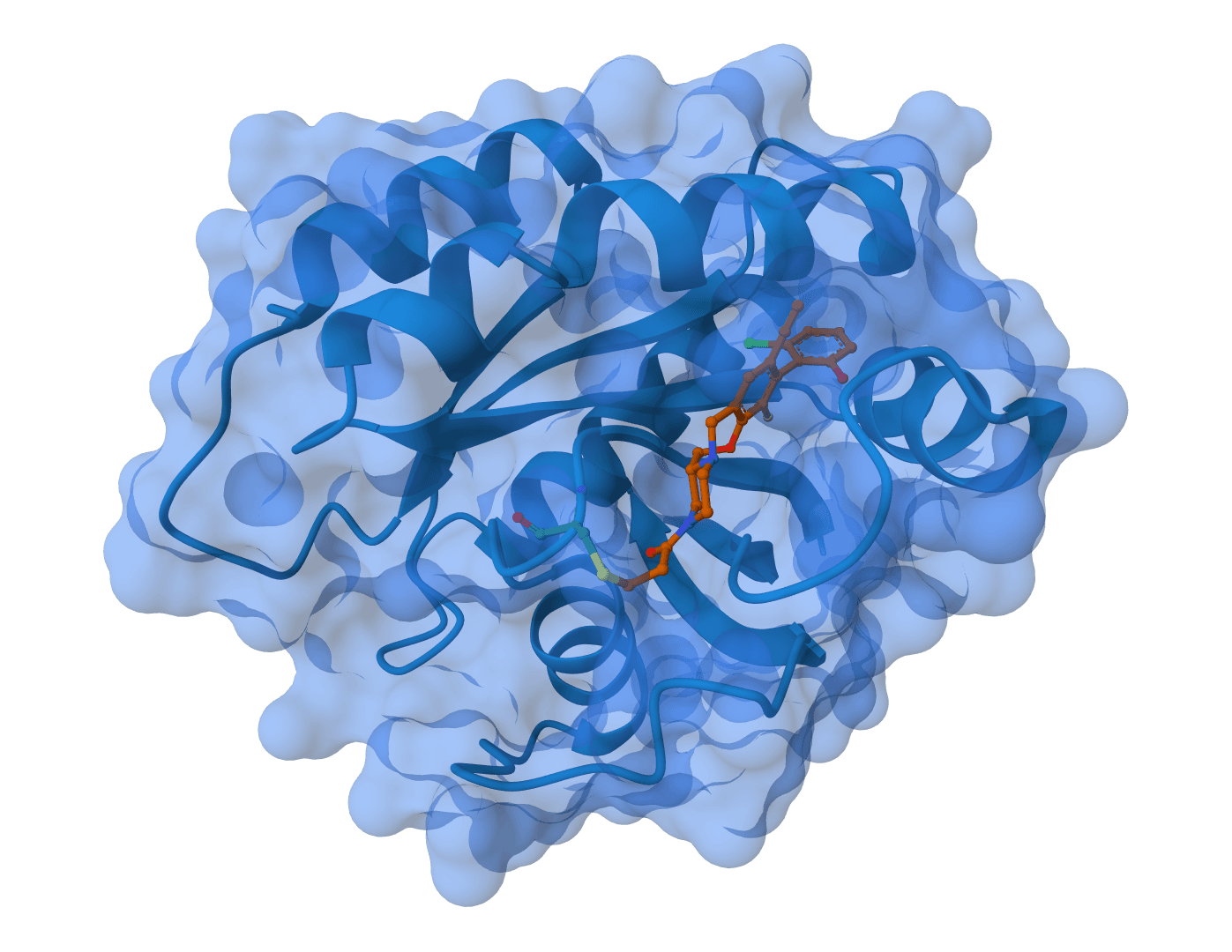
Boltz-2
Boltz-2 is a biomolecular foundation model for structure and binding affinity prediction. Supports proteins, ligands, DNA, and RNA in multi-component complexes. Automatically scales GPU resources for large complexes. Predicts binding affinity with near-FEP accuracy at 1000x faster speed.
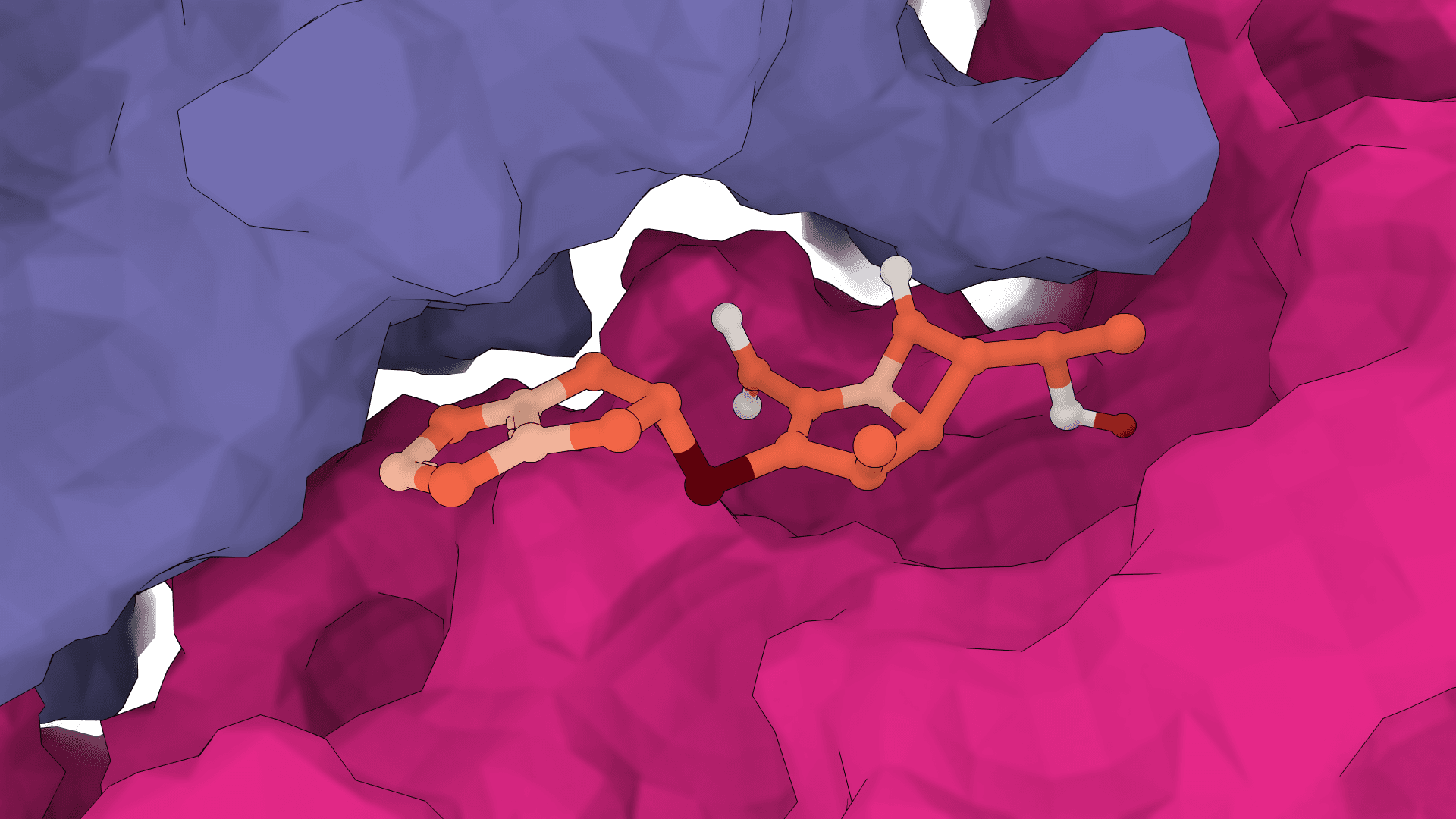
GNINA
GNINA is a molecular docking tool that combines traditional physics-based docking with deep learning CNN scoring for protein-small-molecule complexes. It provides accurate binding predictions with confidence scores, optimized for high-throughput virtual screening.
Read to research?
Free
Per user/month, billed annually
For trying ProteinIQ
- 1,200 credits/year
- Daily lightweight analysis
- Core sequence and format tools
Lite
Per user/month, billed annually
For regular individual research
- 6,000 credits/year
- No daily job limit
- API, assistant, and workflows
Plus
Per user/month, billed annually
For high-throughput workflows
- 24,000 credits/year
- More concurrent jobs
- Batch workflow runs
Pro
Per user/month, billed annually
For commercial research
- 96,000 credits/year
- Commercial license
- Highest self-serve limits
Questions & answers
ProteinIQ supports enzyme engineering workflows for enzyme annotation, substrate context review, activity prediction, kcat-style scoring, mutation and stability screening, structure modeling, and inhibitor or substrate triage. The platform keeps upstream tool outputs available so enzyme decisions can be reviewed rather than treated as black-box results.
ProteinIQ enzyme tools commonly accept enzyme FASTA sequences, PDB structures, substrate SMILES, inhibitor libraries, mutation lists, and tabular inputs depending on the upstream method. Each workflow keeps the accepted input type tied to the tool that generates the activity, stability, or structure output.
Yes. ProteinIQ can compare enzyme variants with mutation, stability, solubility, structure, and activity-related outputs depending on the selected tools. The results are preserved as tables, structure files, logs, and other artifacts so candidate variants can be compared side by side.
ProteinIQ can run enzyme activity and kcat-oriented prediction tools when the required sequence, structure, or substrate inputs are available. These outputs are computational prioritization signals, so ProteinIQ presents the scores and input context for review rather than treating them as measured kinetic constants.
Yes. ProteinIQ can connect enzyme sequences or structures to design, mutation scoring, and stability prediction tools that help prioritize variants for testing. The platform keeps the redesigned sequences, mutation tables, stability scores, and structure evidence tied to the original enzyme context.
Yes. When an enzyme workflow includes compound context, ProteinIQ can help review substrate or inhibitor candidates with structure, docking, property, and ADMET-style evidence depending on the tools selected. These results support triage and experimental planning rather than replacing biochemical validation.
No. ProteinIQ provides computational enzyme engineering and prioritization evidence. Enzyme kinetics, activity, specificity, stability, expression, and substrate-scope claims still require experimental enzyme assays before they should be treated as validated results.
Yes. ProteinIQ enzyme workflows can export CSV score tables, sequence files, predicted or prepared structures, mutation outputs, docking or compound tables, logs, and upstream result artifacts depending on the tool. Exported files preserve the evidence needed for review outside ProteinIQ.
Start in ProteinIQ with an enzyme sequence or structure and choose either a workflow template or a specific tool for activity prediction, stability review, structure modeling, or compound triage. Running a small test input first is the best way to confirm formatting before scaling to larger variant sets.