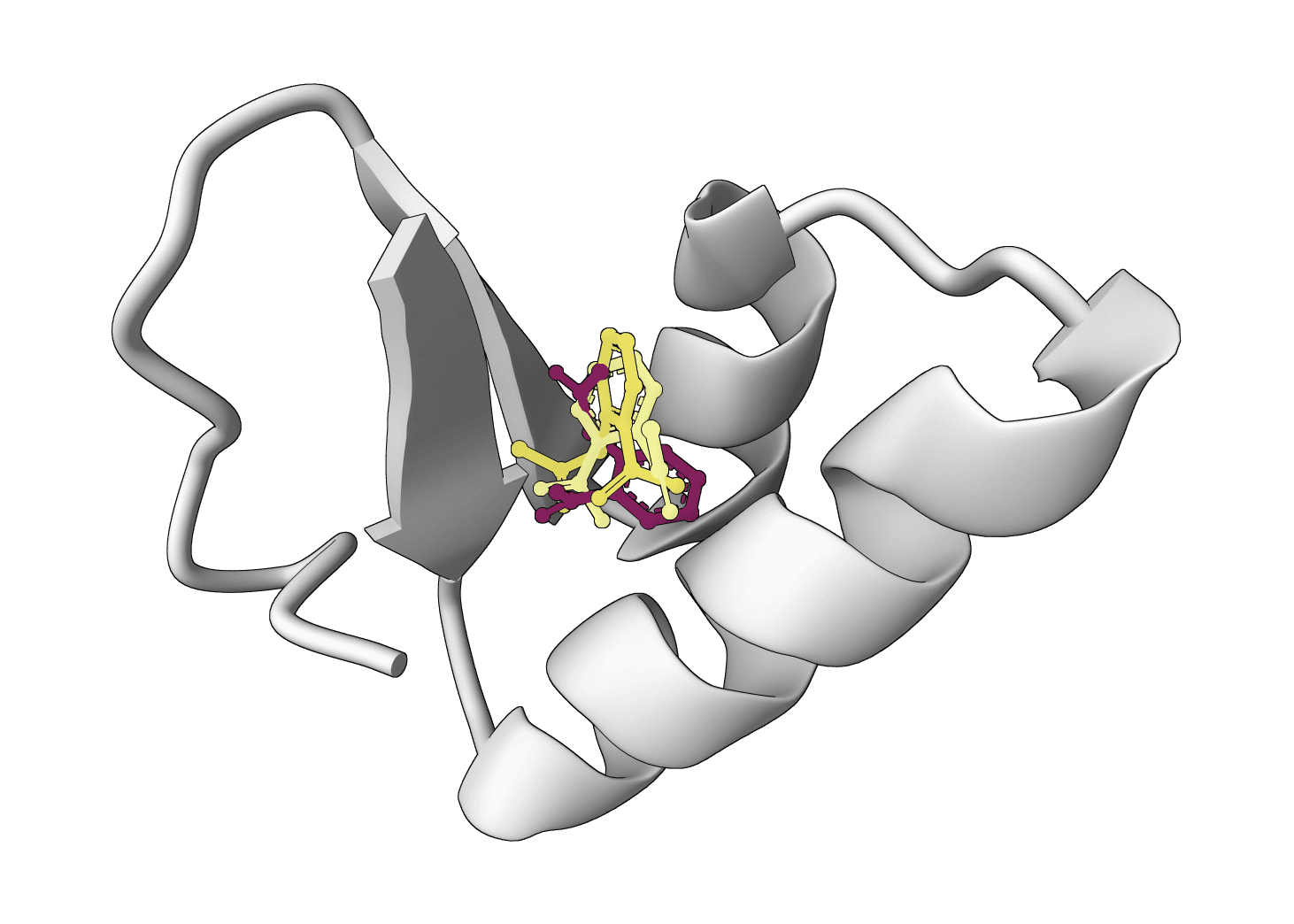What is FlowDock?
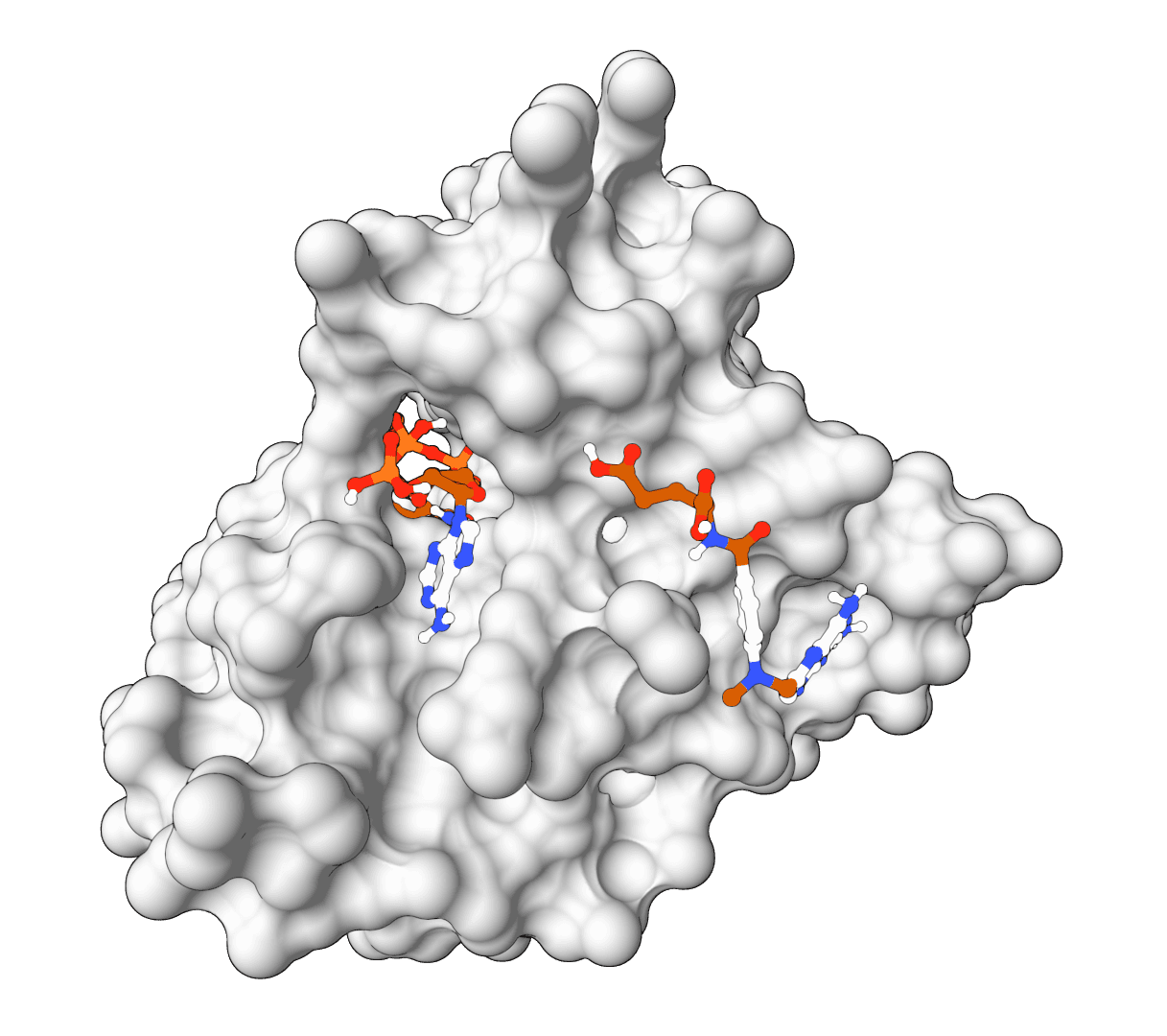
FlowDock predicts the structure of a protein-ligand complex and estimates how tightly the two bind, starting from nothing more than a protein sequence and a ligand SMILES string. It is a generative model: instead of slotting a ligand into a fixed receptor, it builds the bound protein conformation and the docked ligand pose together, then reports a confidence score and an affinity estimate for each sampled complex.
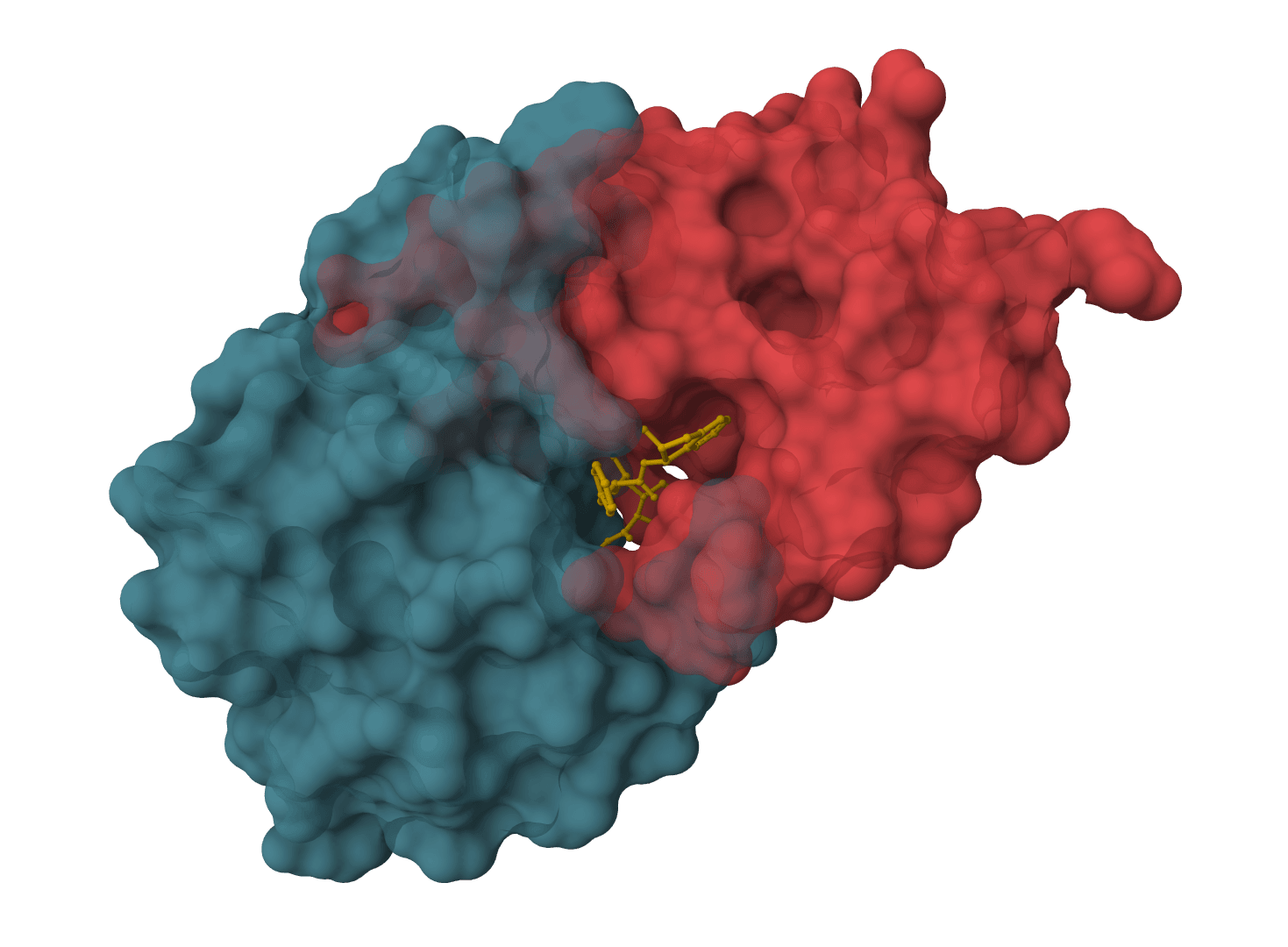
That single trait separates it from most docking tools. Classic docking assumes a known receptor structure and treats the protein as rigid or nearly so. FlowDock generates the holo (bound) protein from an apo prior, so the backbone and side chains can move to accommodate the ligand. The cost of that flexibility is sampling: FlowDock draws several complexes per run and ranks them, rather than returning a single deterministic answer.
The method comes from Alex Morehead and Jianlin Cheng (ISMB 2025). It is most useful when no experimental holo structure exists, when binding may reshape the pocket, or when a fast affinity estimate alongside the pose is more valuable than a single high-resolution docking result.
How to use FlowDock online
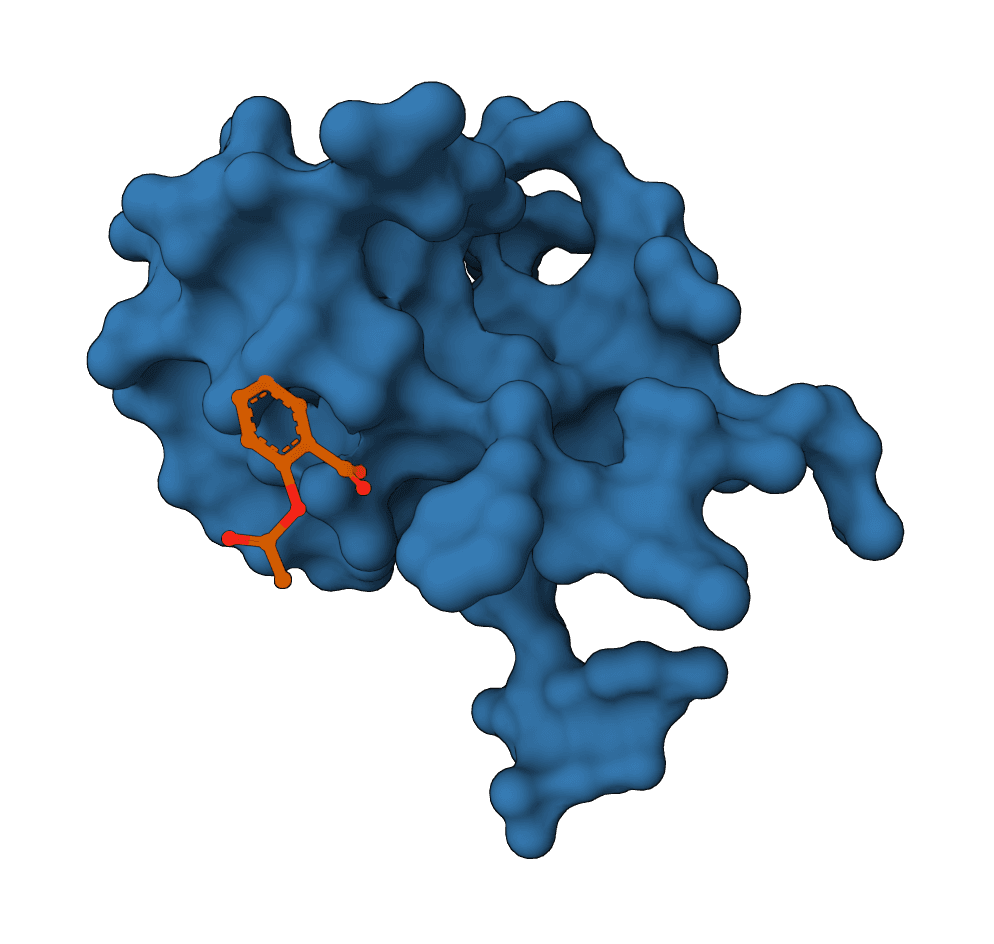
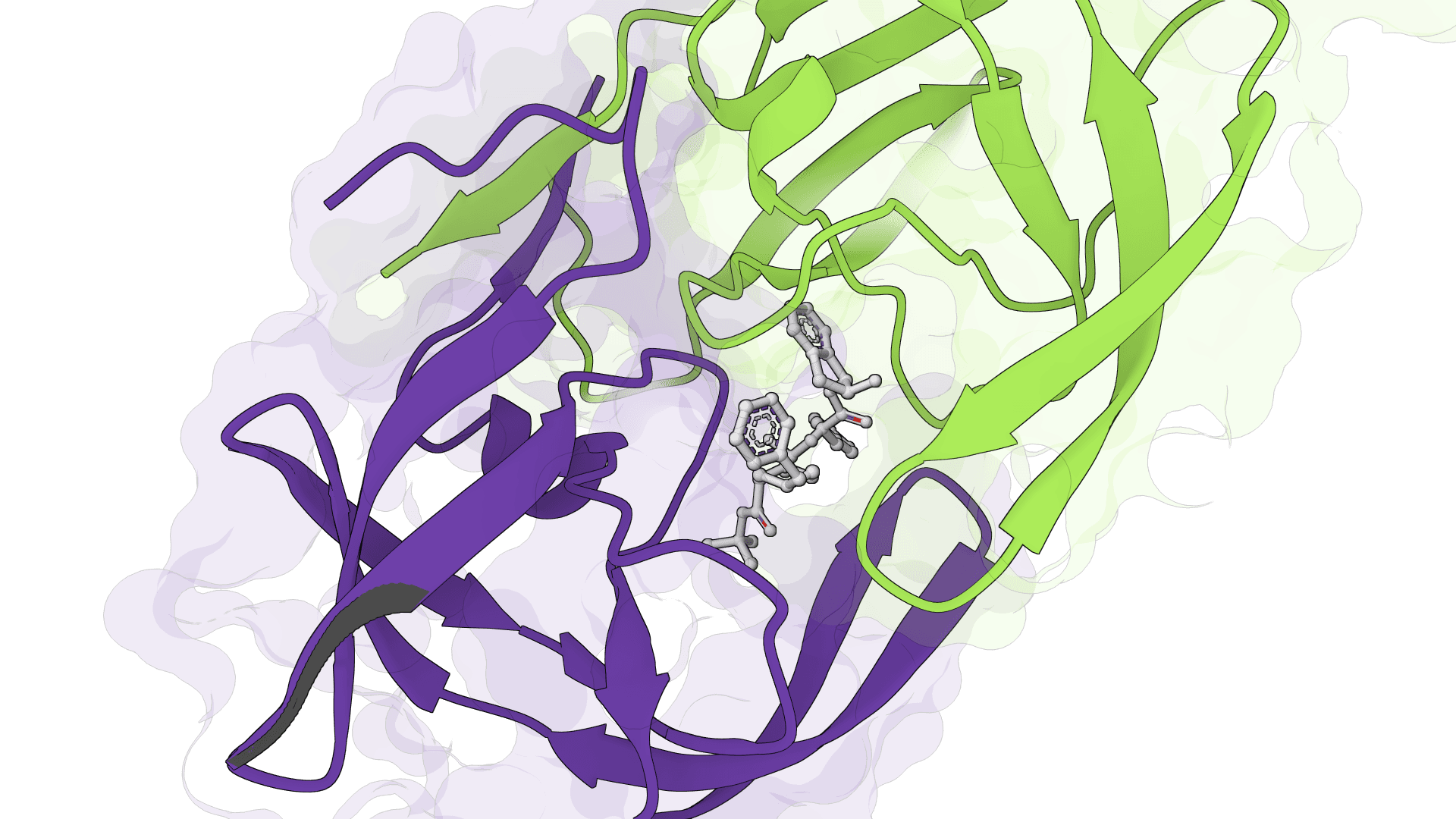
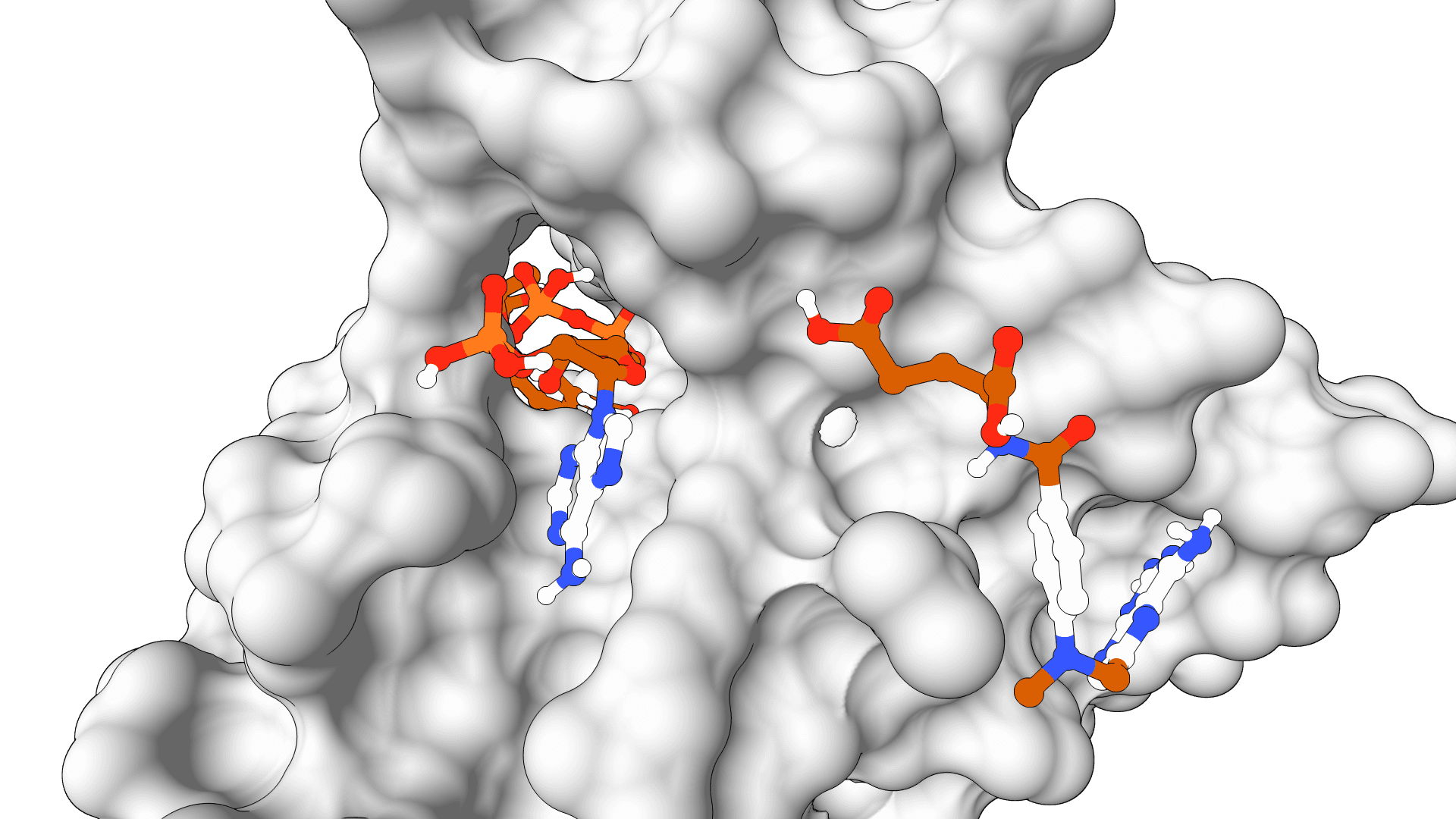
ProteinIQ runs FlowDock on GPU infrastructure with no setup. Provide a protein as a sequence, FASTA, or receptor PDB, and a ligand as a SMILES string or SDF file. FlowDock samples several protein-ligand complexes and returns ranked PDB structures, ranked SDF ligand poses, per-pose plDDT confidence, and an affinity estimate for each, all downloadable. An optional template PDB can guide the structure prior.
Two ProteinIQ tools pair naturally with the inputs here. If only a ligand name or PubChem CID is on hand, fetch the SMILES directly in the ligand card. If the protein is known only by sequence and a starting fold helps, predict one first with ESMFold and pass it as the template.
Settings
FlowDock's defaults reproduce the sampling configuration from the original sample.py, so the out-of-the-box run matches the published method. The settings below mostly trade speed against the number and diversity of sampled complexes.
Outputs
The Data tab summarizes the same results as a sortable table of rank, plDDT, affinity, and source filename, while the Viewer tab loads the sampled complexes for inspection.
How FlowDock works
FlowDock treats docking as a transport problem. It learns a continuous flow that carries an unbound starting structure toward a bound protein-ligand complex, parameterized by conditional flow matching. At inference it integrates that flow over a fixed number of steps, moving atoms from the prior toward a plausible holo state.
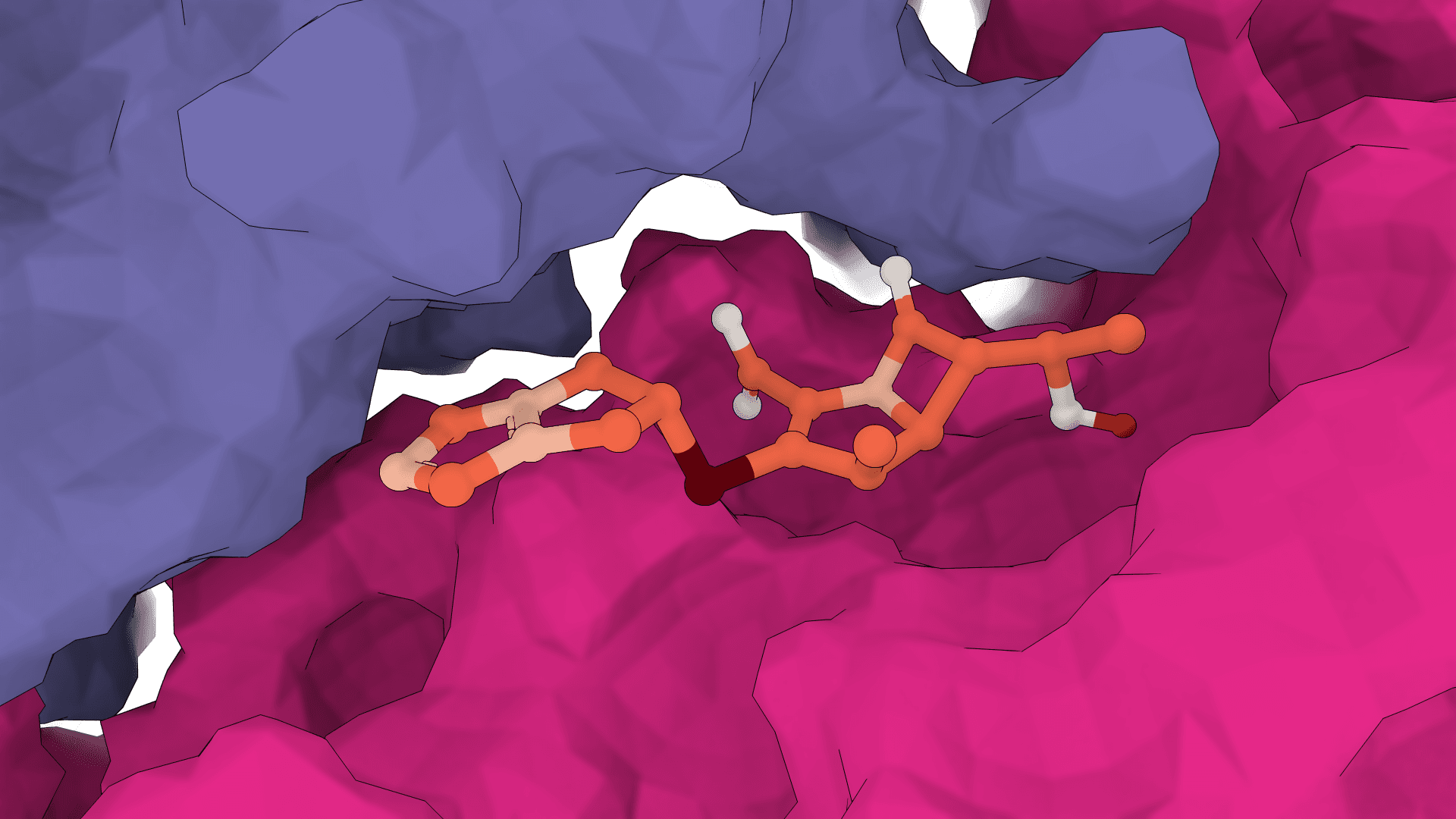
The starting point comes from a structure prior. FlowDock uses an ESMFold-derived apo conformation of the protein, which is why a sequence is enough to start and why a matching template PDB can be supplied to steer the prior. The ligand is initialized from its molecular graph, with input coordinates discarded by default so the pose is sampled rather than copied.
Two auxiliary heads run on top of the generated geometry. A confidence head produces plDDT-style per-residue and per-ligand scores, and an affinity head predicts binding strength. Because generation is stochastic, FlowDock draws several complexes and uses the confidence head to rank them, so the top-ranked file is the model's best guess rather than the only one it considered.
Interpreting results
plDDT here mirrors the confidence metric from structure prediction: higher means the model is more certain about the local geometry it produced. Ligand plDDT speaks to pose reliability, protein plDDT to the backbone and pocket. Treat a high-plDDT top pose as a confident prediction and a run where even the best pose scores low as a signal that the pocket, the ligand, or the prior is hard for the model.
The affinity values are model estimates, not measurements. Use them to rank candidates against each other within a campaign, not as a substitute for an assay or a physics-based free energy. When ranking matters, compare relative affinity across ligands docked the same way rather than reading any single number as an absolute Kd.
Always inspect more than the top file. The ranked SDF and PDB outputs let alternative poses be compared, and a cluster of high-confidence poses that agree on the binding mode is more trustworthy than a single high score. For a physics-based cross-check of the top complex, an MM-PBSA free energy estimate on the ranked structure gives an independent read on binding.
When to use FlowDock vs alternatives
FlowDock fits the case where no holo receptor exists and the pocket may rearrange on binding. It generates the bound protein and ligand together and hands back an affinity estimate in the same run, which classical docking does not.
If a high-quality receptor structure is already in hand and the goal is fast, well-calibrated pose ranking, AutoDock Vina is the leaner choice, and GNINA adds CNN rescoring on the same rigid-receptor setup. For blind docking of a ligand into a known structure without a search box, DiffDock is a closer comparison, though it does not move the protein or score affinity. When the target is a broader complex, including multiple chains or cofactors, the all-atom co-folding models Chai-1, Protenix, and Boltz-2 predict the assembly and, in Boltz-2's case, affinity as well.