Input
10 credits
Output
Configure input settings on the left, then click "Run HMMER"
Perform multiple sequence alignment using MAFFT (Multiple Alignment using Fast Fourier Transform). Supports multiple algorithms from fast progressive to highly accurate iterative methods.
Ultra-fast sequence search and clustering. 10,000x faster than BLAST for database searches, with powerful sequence clustering capabilities for proteins and nucleotides.
Perform multiple sequence alignment using MUSCLE5 (MUltiple Sequence Comparison by Log-Expectation). Uses the PPP algorithm for high-quality alignments with support for ensemble generation.
Analyze immunoglobulin (antibody) and T cell receptor variable domain sequences. Identifies V/D/J gene segments, delineates CDR regions, and analyzes rearrangement junctions.
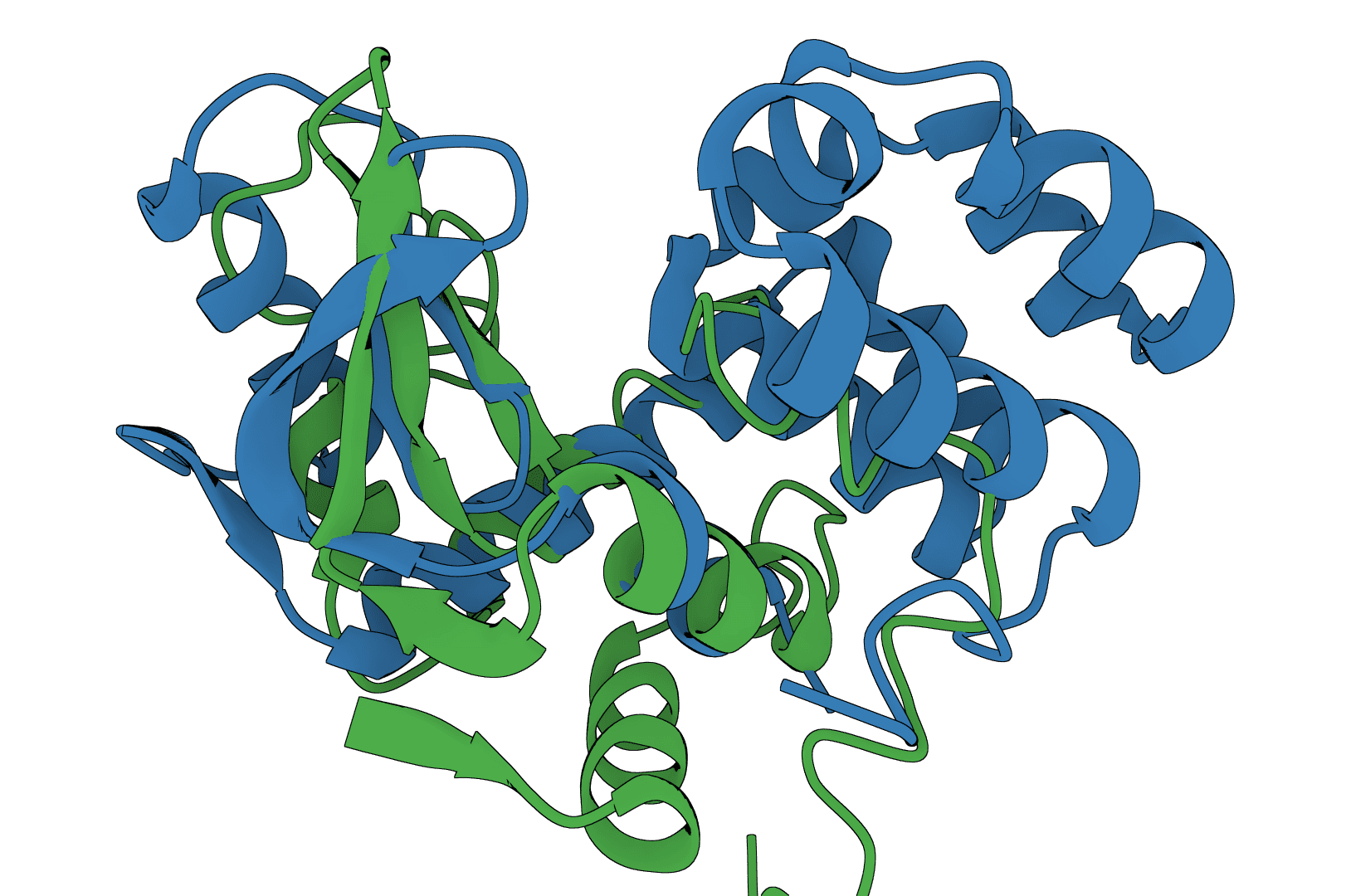
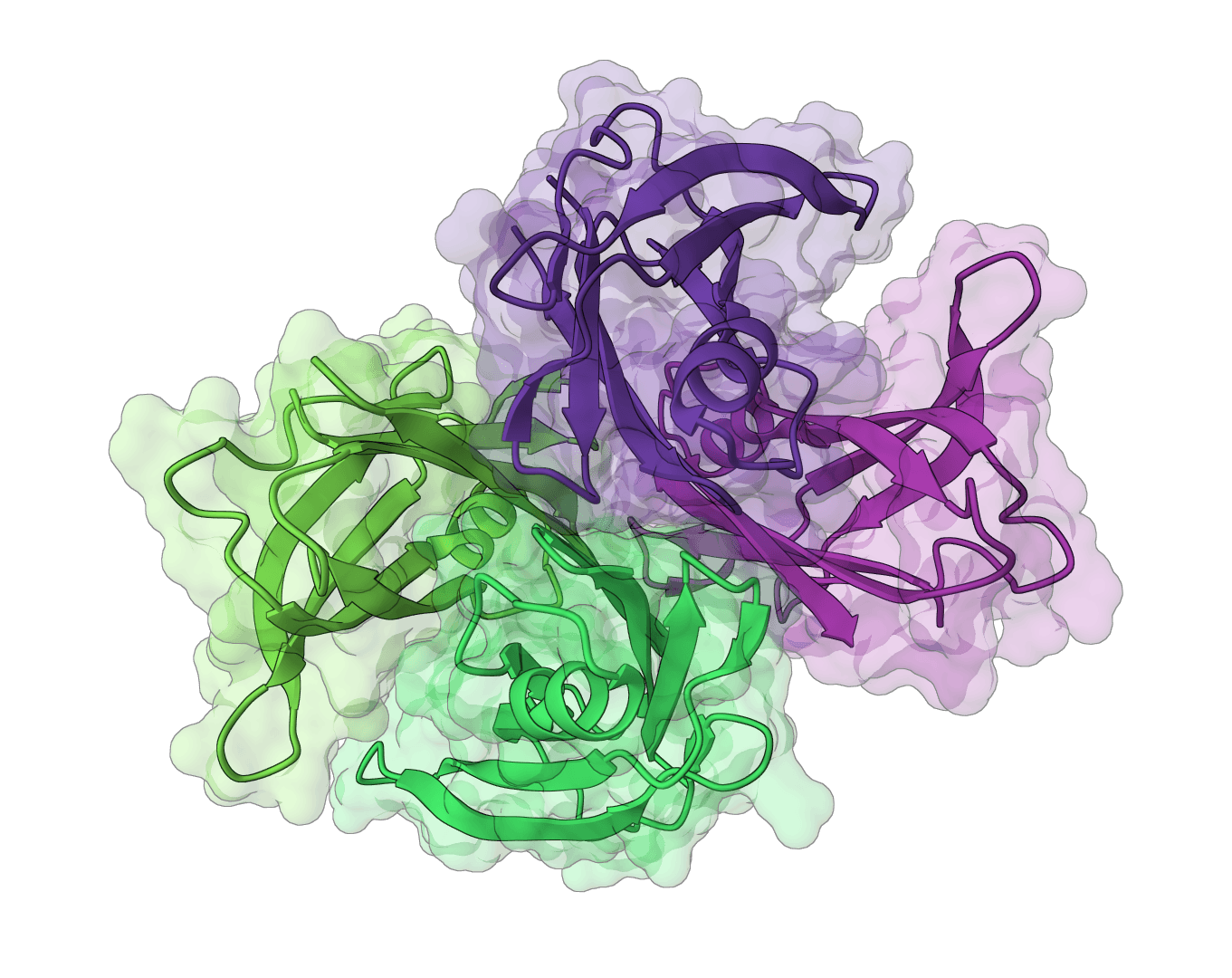
USAlign (Universal Structure Alignment) aligns protein, RNA, and DNA structures to compute TM-scores and generate superposed structures. Compare 3D structures to assess structural similarity.
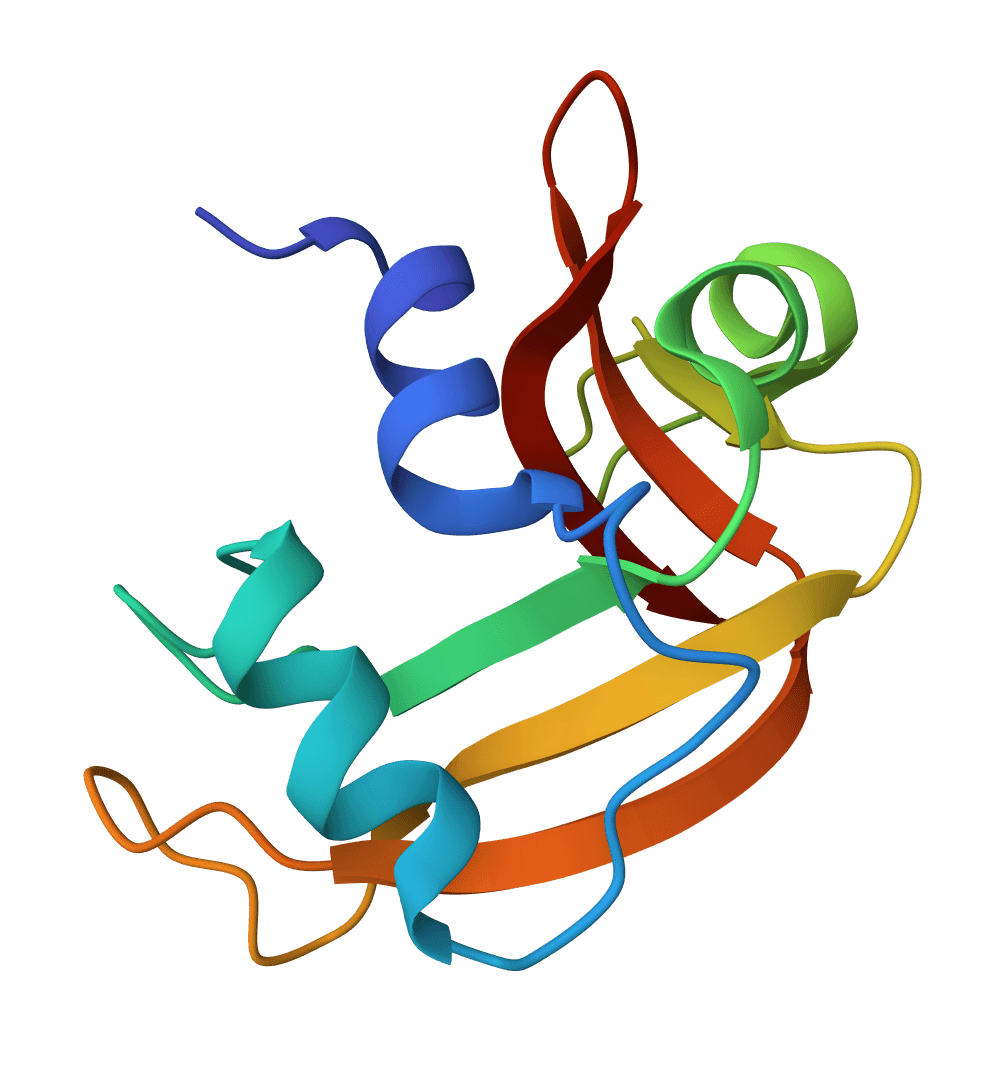
Number antibody and T cell receptor variable domain sequences using multiple numbering schemes (IMGT, Chothia, Kabat, Martin, AHo, Wolfguy). Identifies chain type, species, and assigns germline genes.
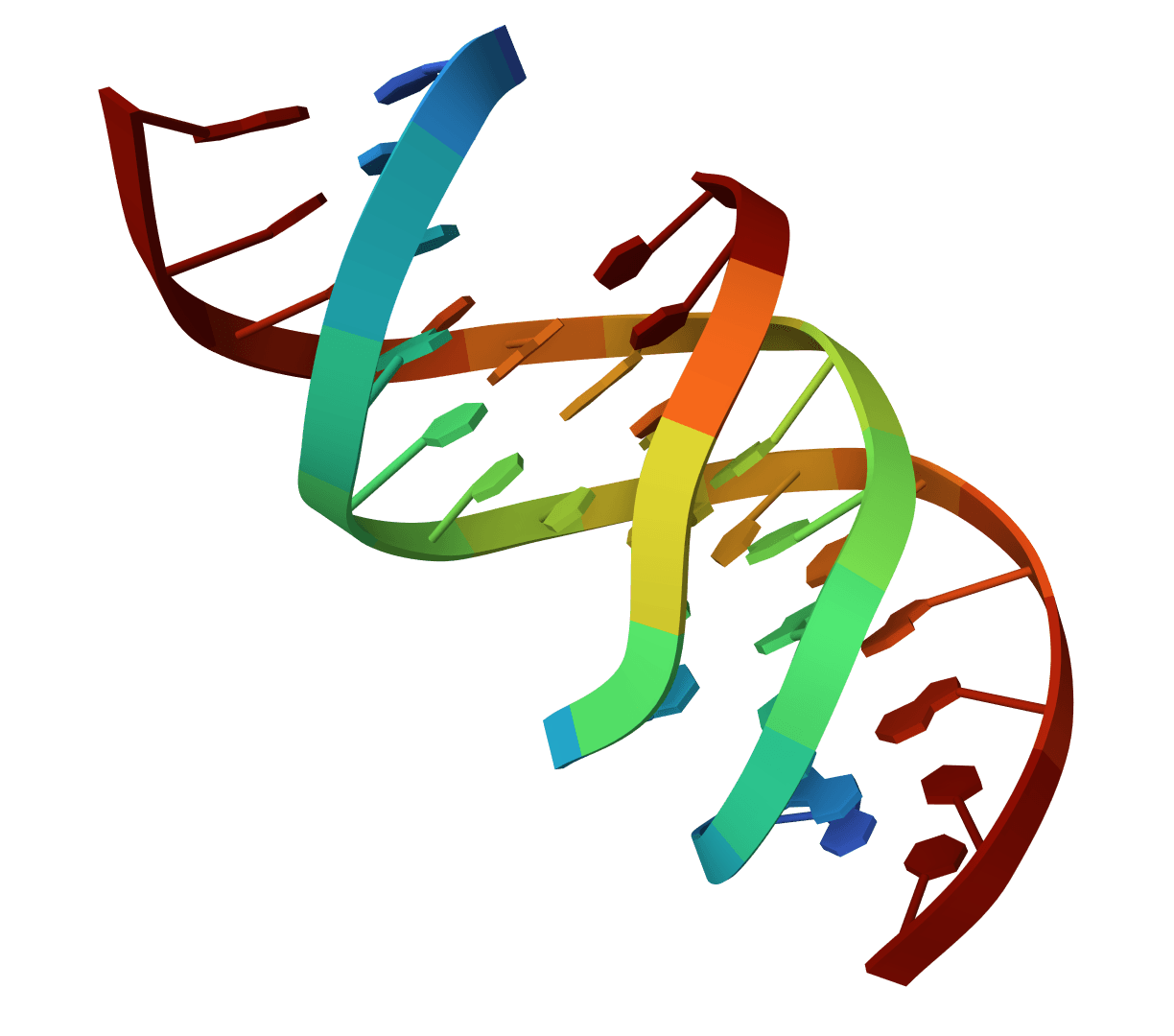
Rapidly align and compare DNA sequences using MUMmer4 nucmer. Perform pairwise genome comparisons to identify SNPs, indels, and structural variants between reference and query genomes.

Perform maximum-likelihood phylogenetic tree inference with RAxML-NG for aligned protein or DNA sequences. Supports ML search, bootstrap analysis, and native automatic model-family selection.
Perform multiple sequence alignment on protein or nucleotide sequences using the Clustal Omega algorithm.
Infer approximately-maximum-likelihood phylogenetic trees from alignments of nucleotide or protein sequences.
HMMER searches biological sequence databases for homologous sequences using profile hidden Markov models (HMMs). Unlike BLAST which uses heuristic methods, HMMER uses probabilistic models to detect remote evolutionary relationships with higher sensitivity.
Profile HMMs turn multiple sequence alignments into position-specific scoring systems. They capture how conserved each position is in a protein family and model insertions and deletions, making them particularly effective for finding distant homologs that BLAST might miss.
For ultra-fast searches on large databases, try MMseqs2, which trades some sensitivity for speed. For structure-based homology detection, use FoldSeek.
A profile HMM is a statistical model that represents a protein family. Each position in the model has probabilities for observing different amino acids, based on how conserved that position is across family members.
The model consists of three types of states at each position:
When HMMER compares your query to a target sequence, it calculates the probability of the target being generated by the profile HMM. This probability is converted to a bit score and E-value.
HMMER offers two search modes with different sensitivity-speed tradeoffs:
The iterative approach makes jackhmmer significantly more sensitive for detecting remote homologs. A protein with only 20% sequence identity to your query might be missed by phmmer but found in jackhmmer's third iteration.
HMMER reports two key statistics for each hit:
The bit score measures how well the target matches the profile HMM. Higher scores indicate better matches. Scores above 20-25 bits generally indicate homology, while scores below 10 bits are likely noise.
The E-value (expectation value) is the number of hits with this score or better expected by chance in a database of this size. An E-value of means you'd expect one false positive per 1,000 database searches.
where is the p-value from the score and is the database size.
E-values below are strong evidence of homology. Values between and suggest possible relatedness. Values above are likely chance matches.
Query sequences should be in FASTA format. You can search with a single sequence or multiple queries. Each query will be searched independently against the target database.
Target sequences/database contains the sequences you want to search for homologs. This can be a custom set of sequences or a large protein database. Larger databases yield higher E-values for the same match quality.
Search mode determines whether to use phmmer or jackhmmer. Use phmmer for fast searches when looking for close homologs. Use jackhmmer when you need maximum sensitivity to detect distant evolutionary relationships.
E-value threshold controls which hits are reported. Lower values are more stringent. For most analyses, is a good balance between sensitivity and specificity.
Maximum hits per query limits the output size. Even with stringent E-value thresholds, some queries may match thousands of sequences in large databases.
Inclusion E-value (jackhmmer only) determines which hits are included in the profile for the next iteration. This should be less stringent than the reporting threshold. Sequences with E-values below this cutoff are added to the profile HMM.
Setting this too low makes jackhmmer converge quickly but may miss true positives. Setting it too high includes false positives in the profile, degrading sensitivity.
Maximum iterations (jackhmmer only) stops the search after this many rounds, even if it hasn't converged. Most searches converge within 3-5 iterations. If your search hits the maximum without converging, the query may be too promiscuous or the threshold too loose.
Results are returned as a tab-separated table with one row per hit:
Query identifies which input sequence produced this hit. If you searched multiple queries, each is reported separately.
Target is the name of the matching sequence from the database. This corresponds to the FASTA header.
E-value is the statistical significance of the match. Lower is better:
Score (in bits) measures match quality. Unlike E-values, scores are not corrected for database size. A score of 30 bits means the match is times more likely under the HMM than by chance.
Bias indicates compositional bias correction applied to the score. High bias values (>10) suggest the match might be driven by biased composition (e.g., low complexity regions) rather than true homology.
Included (jackhmmer only) shows whether this hit was used to build the profile in iterative rounds. Only hits meeting the inclusion threshold become part of the growing profile HMM.
HMMER excels at several common bioinformatics tasks:
Finding protein family members across multiple species. Search with a known family member to identify orthologs and paralogs. The profile HMM approach handles variation across species better than simple sequence comparison.
Annotating unknown sequences by finding their closest characterized relatives. If a newly sequenced protein matches a well-studied family with , it likely shares their function.
Detecting distant homologs that diverged long ago. Proteins with only 20-30% sequence identity can be reliably detected with jackhmmer, while BLAST might miss them.
Building profile HMMs for downstream analysis. The HMMs generated by jackhmmer can be used to search much larger databases or to classify new sequences.
HMMER's sensitivity comes with computational cost. Searching large databases can take several minutes. For very large-scale searches where speed is critical, consider MMseqs2, which is orders of magnitude faster with slightly reduced sensitivity.
Short queries (less than 25 residues) may produce unreliable statistics. The profile HMM needs sufficient information to distinguish signal from noise.
Compositional bias can inflate scores. Sequences rich in one amino acid (e.g., polyglutamine tracts) may score well by chance. The bias score helps identify these false positives.
jackhmmer can diverge if the inclusion threshold is too permissive. Including false positives in early rounds pollutes the profile, causing it to match unrelated sequences in later iterations.