Input
5 credits
Output
Configure input settings on the left, then click "Build Tree"
Perform multiple sequence alignment on protein or nucleotide sequences using the Clustal Omega algorithm.
Build phylogenetic trees using maximum likelihood with automatic model selection (ModelFinder) and ultrafast bootstrap support.
Perform multiple sequence alignment using MAFFT (Multiple Alignment using Fast Fourier Transform). Supports multiple algorithms from fast progressive to highly accurate iterative methods.
Perform multiple sequence alignment using MUSCLE5 (MUltiple Sequence Comparison by Log-Expectation). Uses the PPP algorithm for high-quality alignments with support for ensemble generation.
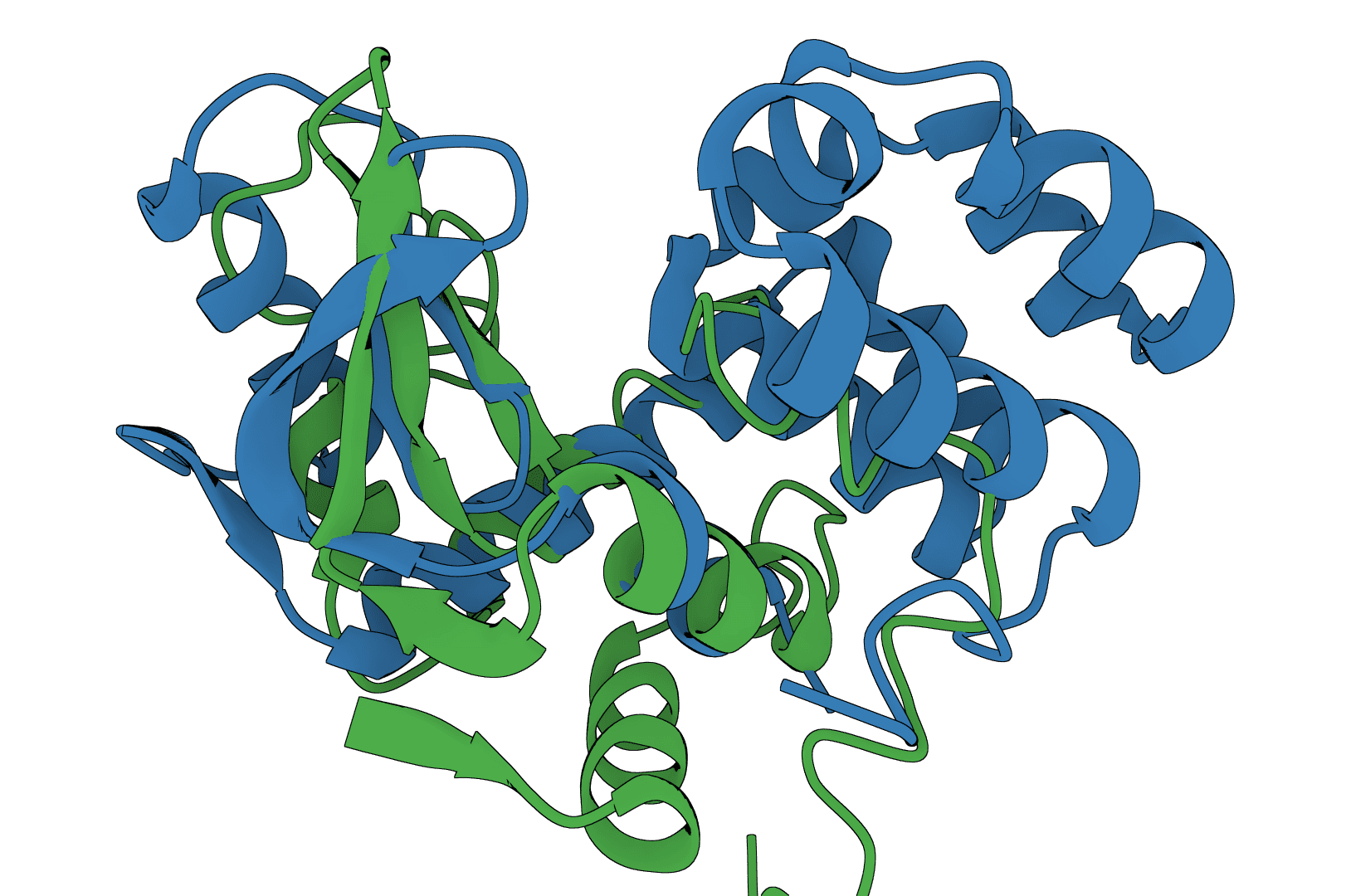
USAlign (Universal Structure Alignment) aligns protein, RNA, and DNA structures to compute TM-scores and generate superposed structures. Compare 3D structures to assess structural similarity.
Ultra-fast sequence search and clustering. 10,000x faster than BLAST for database searches, with powerful sequence clustering capabilities for proteins and nucleotides.
Rapidly align and compare DNA sequences using MUMmer4 nucmer. Perform pairwise genome comparisons to identify SNPs, indels, and structural variants between reference and query genomes.
RNAalifold computes consensus RNA secondary structure from a multiple sequence alignment. Uses covariation information to improve prediction accuracy for evolutionarily conserved structures.

Quantify transcript abundance from RNA-seq reads with Salmon selective alignment. Upload a transcript FASTA reference plus single-end or paired-end FASTA/FASTQ reads to produce TPM and estimated read-count tables.
Sensitive sequence homology search using profile hidden Markov models. More accurate than BLAST for detecting remote homologs, ideal for finding evolutionarily distant protein family members.
FastTree builds approximately-maximum-likelihood phylogenetic trees from multiple sequence alignments. It can handle alignments with up to a million sequences while remaining computationally efficient—100 to 1,000 times faster than traditional maximum-likelihood methods like PhyML or RAxML.
Phylogenetic trees visualize evolutionary relationships between sequences. Branch lengths represent evolutionary distance (substitutions per site), while the tree topology shows which sequences share common ancestors. FastTree is particularly useful for large-scale studies where traditional ML methods would be prohibitively slow.
Important: FastTree requires pre-aligned sequences (a Multiple Sequence Alignment). All sequences must be the same length with homologous positions aligned in the same column. If your sequences aren't aligned, you'll need to align them first using tools like Clustal Omega or MUSCLE before using FastTree.
FastTree uses a three-phase approach to build phylogenetic trees efficiently.
FastTree first builds a rough starting tree using a heuristic variant of neighbor-joining. Instead of storing a full distance matrix (which would require memory), FastTree stores sequence profiles at internal nodes. This optimization allows it to handle much larger alignments than traditional methods.
Three heuristics speed up this phase: remembering the best join for each node, hill-climbing search for better joins, and the "top-hits" heuristic to avoid computing all pairwise distances.
The initial tree is improved using nearest-neighbor interchanges (NNI) and subtree-pruning-regrafting (SPR) moves under the minimum evolution criterion. FastTree performs rounds of NNIs and 2 rounds of SPRs by default.
SPR moves are computationally expensive ( possibilities), so FastTree treats them as chains of NNIs and only extends promising candidates.
Finally, FastTree performs maximum-likelihood NNI moves to optimize the tree topology. The CAT approximation assigns each alignment site to one of 20 rate categories, accounting for varying evolutionary rates across positions without the computational cost of full gamma-distributed rates.
FastTree supports different substitution models depending on your sequence type.
FastTree accepts sequences in FASTA format. All sequences must be aligned (same length) before submission.
Sequence names cannot contain the characters : , ( ) as these have special meaning in Newick tree format.
FastTree auto-detects whether your alignment contains protein or nucleotide sequences. You can override this if needed—select Nucleotide for DNA/RNA sequences or Protein for amino acid sequences.
Choose the amino acid substitution matrix. JTT works well for most cases. Try WAG or LG if you're working with specific protein families where these models have been shown to perform better.
For nucleotide sequences, the GTR model accounts for different substitution rates (e.g., transitions vs transversions). We recommend enabling this for DNA/RNA alignments.
Rescales branch lengths using the Gamma20 likelihood, which more accurately models rate variation across sites. This adds approximately 5% to computation time but provides more accurate branch length estimates.
Speeds up neighbor-joining approximately 4-fold. We recommend enabling this for alignments with more than 50,000 sequences.
By default, FastTree reports SH-like local support values. Setting bootstrap resamples > 0 performs traditional bootstrap analysis instead, which resamples alignment columns and rebuilds trees to assess branch support.
FastTree outputs a phylogenetic tree in Newick format, which our interactive viewer renders automatically.
Branch lengths represent evolutionary distance in substitutions per site. Longer branches indicate more sequence divergence. Closely related sequences (like proteins from the same species) will have short branches between them.
Numbers at internal nodes indicate statistical support for that split in the tree. FastTree reports SH-like local supports ranging from 0 to 1 by default. Values above 0.9 indicate well-supported branches; values below 0.7 suggest uncertainty in that part of the tree.
The branching pattern shows inferred evolutionary relationships. Sequences that cluster together share a more recent common ancestor than sequences on distant branches.
FastTree prioritizes speed over maximum accuracy. For datasets where topological accuracy is critical, consider using slower but more thorough methods like IQ-TREE or RAxML for final analysis.
The CAT approximation, while fast, is less accurate than full discrete gamma models for estimating rate variation. If you need precise branch lengths, enable Gamma optimization.