Input
50 credits
Output
Configure input settings on the left, then click "Run FoldSeek"
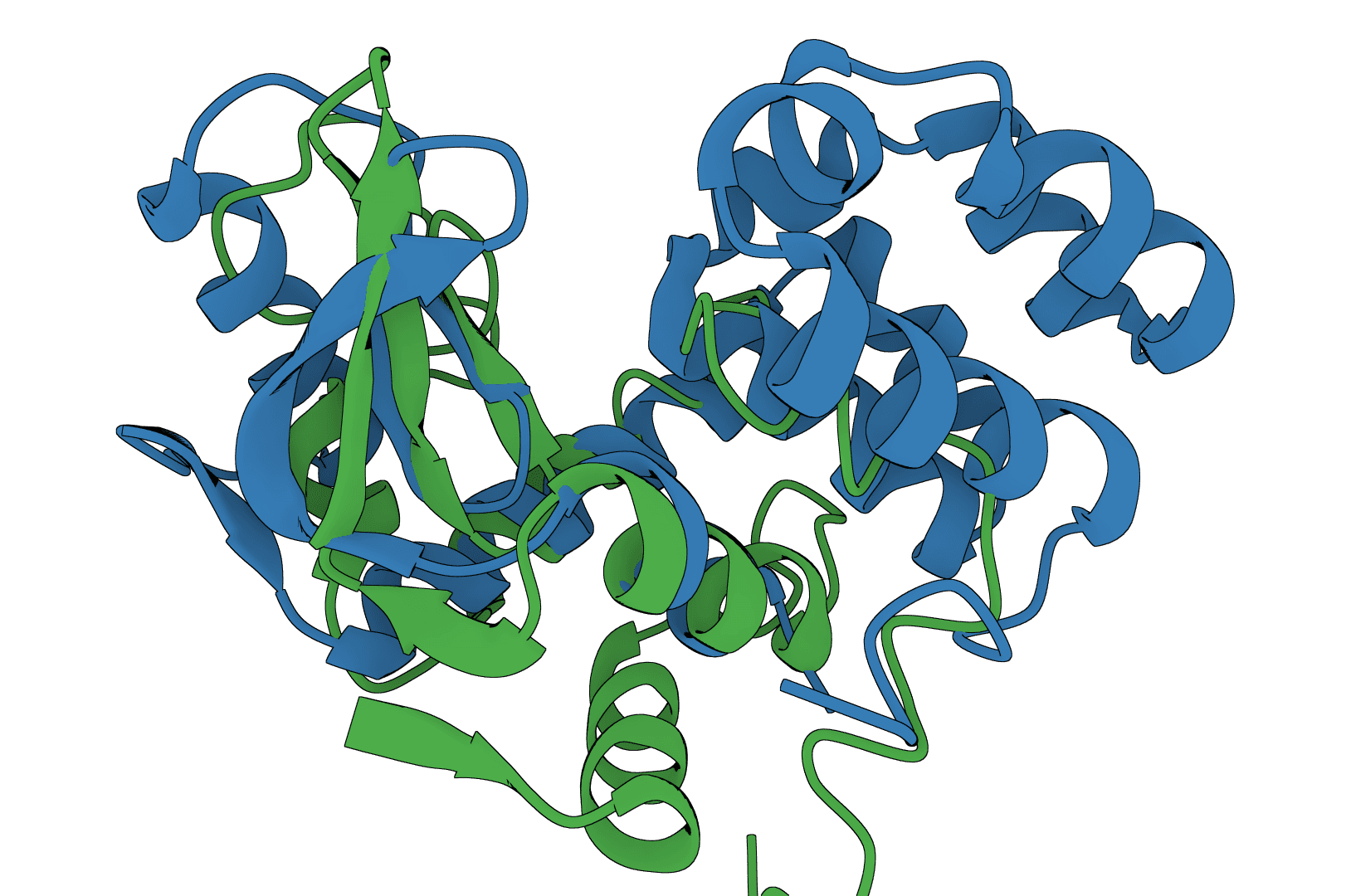
USAlign (Universal Structure Alignment) aligns protein, RNA, and DNA structures to compute TM-scores and generate superposed structures. Compare 3D structures to assess structural similarity.
Number antibody and T cell receptor variable domain sequences using multiple numbering schemes (IMGT, Chothia, Kabat, Martin, AHo, Wolfguy). Identifies chain type, species, and assigns germline genes.
Analyze immunoglobulin (antibody) and T cell receptor variable domain sequences. Identifies V/D/J gene segments, delineates CDR regions, and analyzes rearrangement junctions.
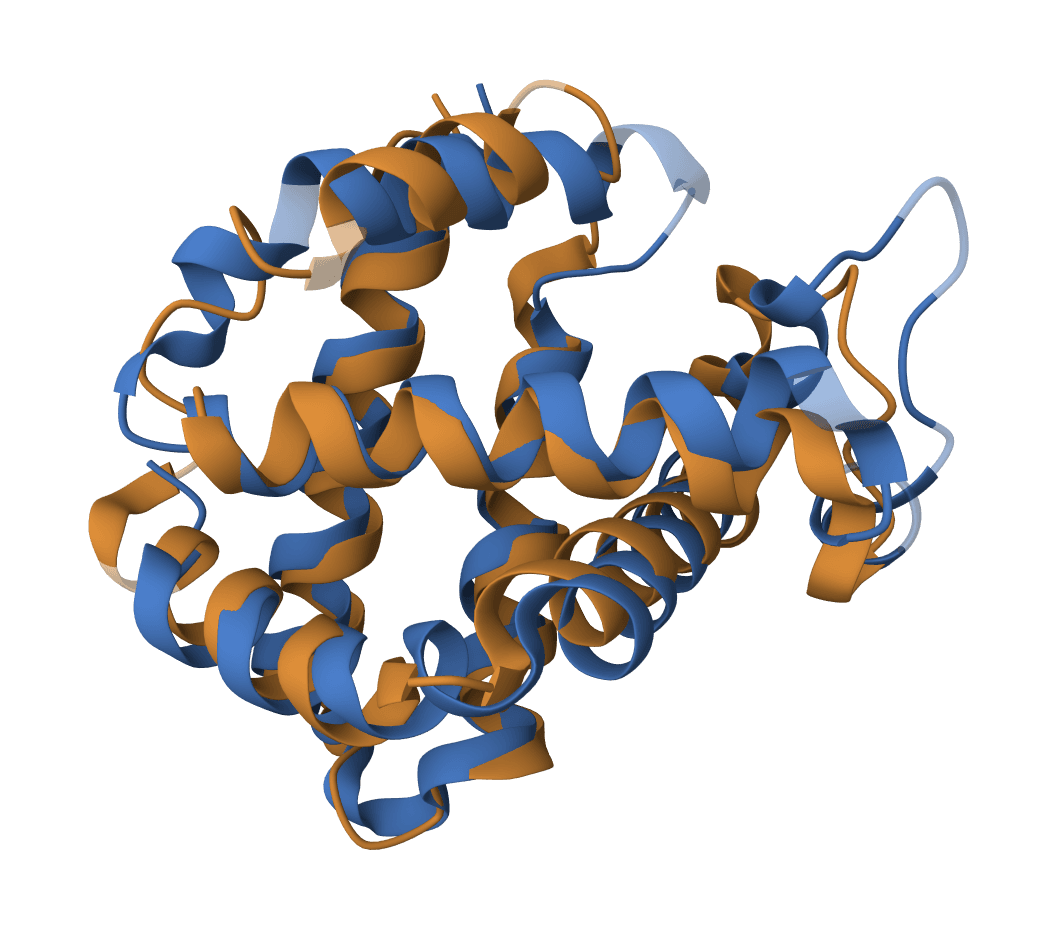
Perform multiple sequence alignment using MAFFT (Multiple Alignment using Fast Fourier Transform). Supports multiple algorithms from fast progressive to highly accurate iterative methods.
Perform multiple sequence alignment using MUSCLE5 (MUltiple Sequence Comparison by Log-Expectation). Uses the PPP algorithm for high-quality alignments with support for ensemble generation.
Rapidly align and compare DNA sequences using MUMmer4 nucmer. Perform pairwise genome comparisons to identify SNPs, indels, and structural variants between reference and query genomes.
Perform multiple sequence alignment on protein or nucleotide sequences using the Clustal Omega algorithm.
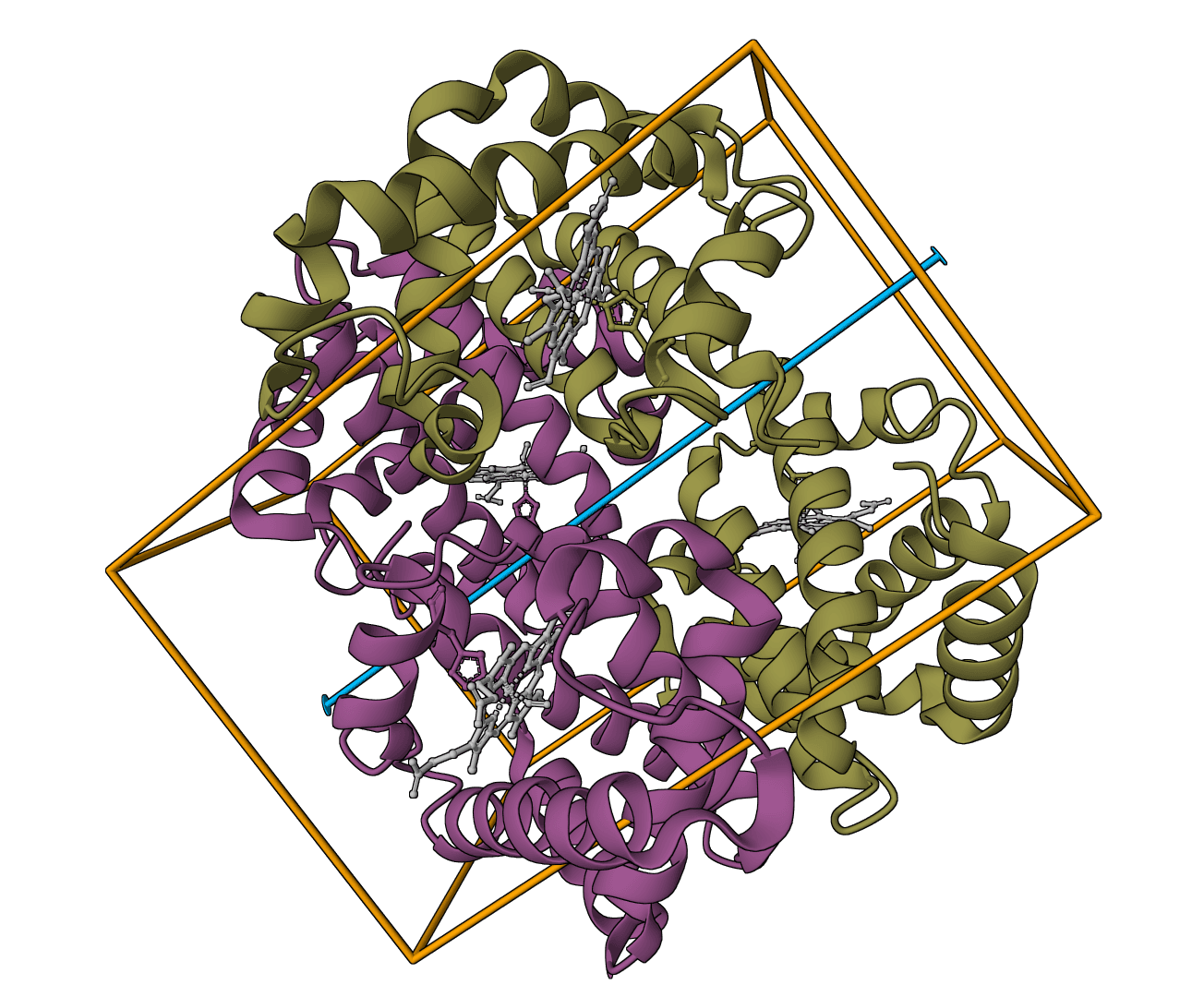
Infer approximately-maximum-likelihood phylogenetic trees from alignments of nucleotide or protein sequences.
Sensitive sequence homology search using profile hidden Markov models. More accurate than BLAST for detecting remote homologs, ideal for finding evolutionarily distant protein family members.
Build phylogenetic trees using maximum likelihood with automatic model selection (ModelFinder) and ultrafast bootstrap support.
FoldSeek is a fast protein structure search tool that can search your structure against 200+ million predicted structures in the AlphaFold Database, compare structures in detail, or cluster multiple structures by similarity.
Traditional structure comparison methods like TM-align are accurate but slow, requiring seconds per comparison. FoldSeek achieves comparable sensitivity while being four to five orders of magnitude faster. This speed comes from a novel encoding approach that converts 3D coordinates into searchable sequences.
For sequence-based clustering, use MMseqs2. For detailed pairwise structure alignment with superposition, use USAlign.
Upload a single structure to search against massive structure databases. Database search uses the FoldSeek web server API, giving you access to the same search capabilities as search.foldseek.com.
Available databases:
| Database | Contents | Size |
|---|---|---|
| AlphaFold DB 50 | Clustered AlphaFold predictions | ~50M representatives |
| PDB | Experimental structures from Protein Data Bank | ~220K structures |
| AlphaFold Swiss-Prot | High-quality curated AlphaFold predictions | ~500K structures |
| CATH 50 | Protein domain database (Class, Architecture, Topology, Homology) | ~30K domains |
By default, AlphaFold DB 50 and PDB are searched. You can enable or disable individual databases in the settings. Database search typically completes in 1-5 minutes depending on server load.
FoldSeek's speed comes from the 3Di (3D interaction) alphabet, which encodes protein structure as a sequence of 20 letters. Unlike traditional backbone structural alphabets, 3Di describes the geometric relationship between each residue and its spatially closest neighbor.
For each residue , FoldSeek finds its nearest neighbor residue based on virtual center distance. Seven angles, the distance, and two sequence distance features are extracted from the backbone coordinates of both residues. These 10 features define the 20 3Di states through a neural network trained to maximize evolutionary conservation.
This encoding has three advantages over backbone alphabets: weaker dependency between consecutive letters, more evenly distributed state frequencies, and higher information density in conserved protein cores rather than loop regions.
FoldSeek converts both query and target structures into 3Di sequences. It then applies the MMseqs2 prefilter to find candidate matches using spaced k-mer matching on diagonals of the alignment matrix. This prefilter reduces the search space by several orders of magnitude while maintaining high sensitivity.
For hits passing the prefilter, FoldSeek performs Smith-Waterman local alignment combining both 3Di and amino acid substitution scores. The final alignment uses structural superposition to calculate TM-score and LDDT.
FoldSeek automatically detects the appropriate mode based on how many structures you upload:
| Structures | Mode | Description |
|---|---|---|
| 1 | Database search | Search against AlphaFold DB, PDB, and other databases |
| 2 | Pairwise comparison | Detailed comparison with TM-score, LDDT, alignment metrics |
| 3+ | Clustering | Group structures by similarity |
You can also explicitly select a mode:
FoldSeek supports two alignment algorithms:
3Di + Sequence: Combines structural and sequence information. Recommended for most use cases as it balances speed and accuracy.TMalign: Pure structural alignment using the TM-align algorithm. Slower but may find more distant structural similarities.When using database search mode, you can select which databases to search:
These settings apply only to local comparison and clustering modes:
0.001) are more stringent and return only confident matches. Increase to find more distant structural relationships.0 to cluster purely by structure.0.5 groups structures with the same fold.FoldSeek returns different metrics depending on the mode. Database search provides probability scores and E-values, while local comparison provides detailed structural metrics.
When searching against AlphaFold DB or PDB, results include:
0.001 are typically considered confident hits.When comparing structures locally (pairwise or clustering mode), FoldSeek calculates:
TM-score (Template Modeling score) measures global structural similarity on a scale of 0 to 1:
| TM-score | Interpretation |
|---|---|
| < 0.17 | Random, unrelated structures |
| 0.17 - 0.5 | Some structural similarity |
| > 0.5 | Same fold |
| 1.0 | Identical structures |
A TM-score of 0.5 is the widely accepted threshold for determining whether two proteins share the same fold. Below 0.17, structures are statistically indistinguishable from random pairs.
LDDT (Local Distance Difference Test) evaluates local structural accuracy without requiring superposition. It compares interatomic distances rather than absolute positions, making it robust to domain movements.
| LDDT | Interpretation |
|---|---|
| > 0.9 | Excellent local agreement |
| 0.7 - 0.9 | Good local structure |
| 0.5 - 0.7 | Moderate agreement |
| < 0.5 | Poor local similarity |
LDDT is particularly useful for multi-domain proteins where global superposition may be misleading.
Sequence identity: The fraction of aligned positions with identical amino acids. High sequence identity with low structural similarity may indicate conformational changes. Low sequence identity with high TM-score indicates structural conservation despite sequence divergence.
FoldSeek excels at finding structural similarity but has some constraints: