Input
Output
Configure input settings on the left, then click "Submit job"
Structure-based de novo antibody and nanobody design pipeline combining antibody-tuned RFdiffusion, ProteinMPNN sequence design, and antibody-tuned RoseTTAFold2 filtering.
Humatch is an antibody humanization tool that transforms non-human antibody sequences into humanized variants. Uses three lightweight CNNs to identify optimal human V-genes and generate paired heavy and light chain sequences with minimal edits while maintaining functionality.
Design antibody CDR sequences via inverse folding. Generates complementarity-determining region (CDR) sequences for antibodies targeting therapeutic antigens using deep learning. Optimizes CDR loops (HCDR1, HCDR2, HCDR3) based on antibody-antigen complex structures.
Inverse folding for antibody variable domains and nanobodies. Predicts amino acid sequences compatible with antibody structures using IMGT numbering while preserving native AntiFold chain handling and structural constraints.
BoltzGen is a state-of-the-art AI model for designing protein and peptide binders against any biomolecular target. Using generative diffusion models, it creates novel binders (proteins, peptides, nanobodies) with nanomolar-level binding affinity.
Reasoning-guided antibody CDR co-design for antibody-antigen complexes. Proteo-R1 identifies residue-level functional decisions and uses conditional diffusion to generate ranked designed structures with confidence metrics.
Antibody humanization and humanness evaluation platform from Merck. Sapiens mode uses deep learning trained on the Observed Antibody Space (OAS) to humanize antibody sequences, while OASis mode evaluates humanness using 9-mer peptide search against human antibody databases.
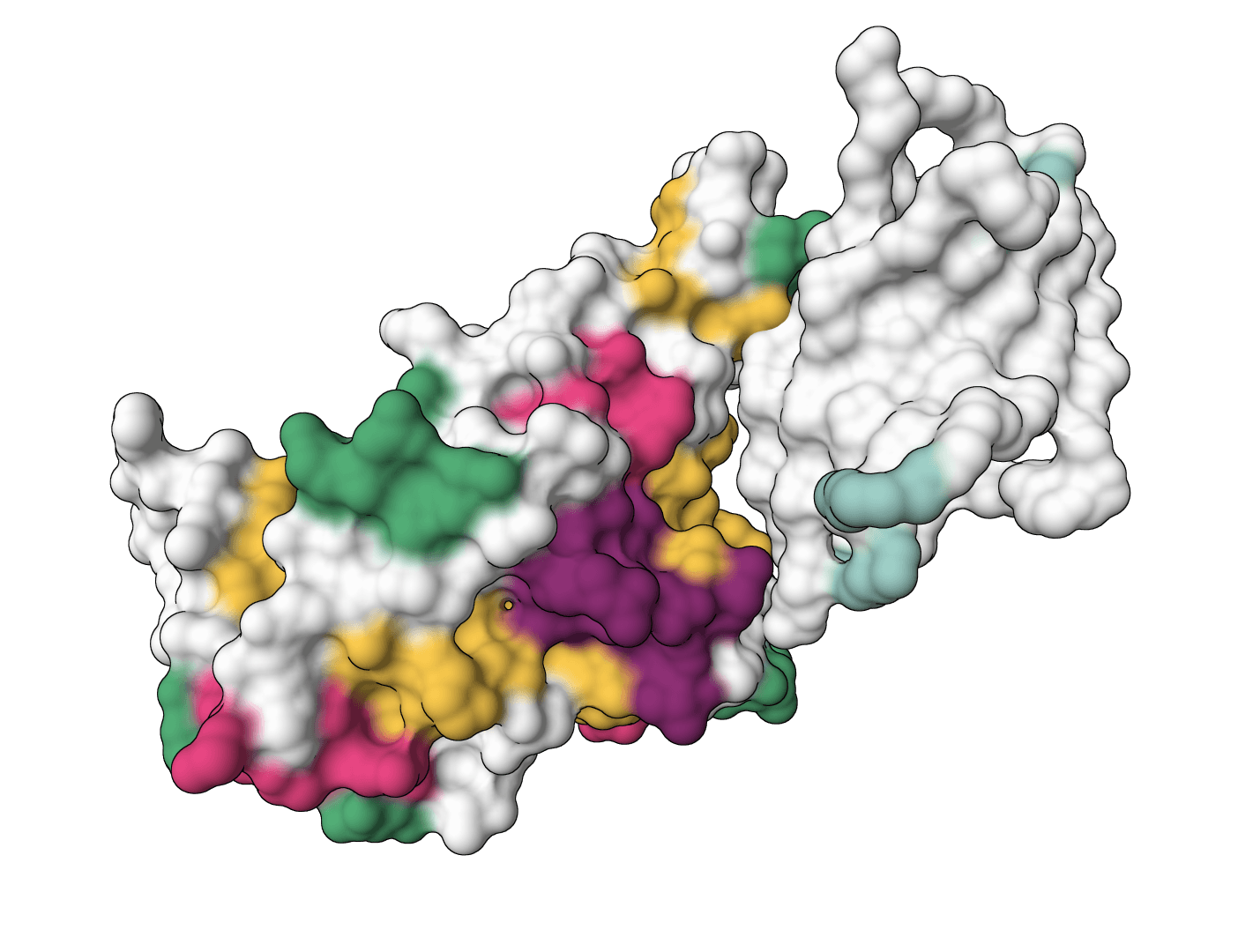
IgGM is a generative foundation model for antibody and nanobody design against a target antigen. Supports CDR design, affinity maturation, inverse design, and framework design. Requires an antigen structure (PDB) and antibody sequences with "X" marking positions to design.
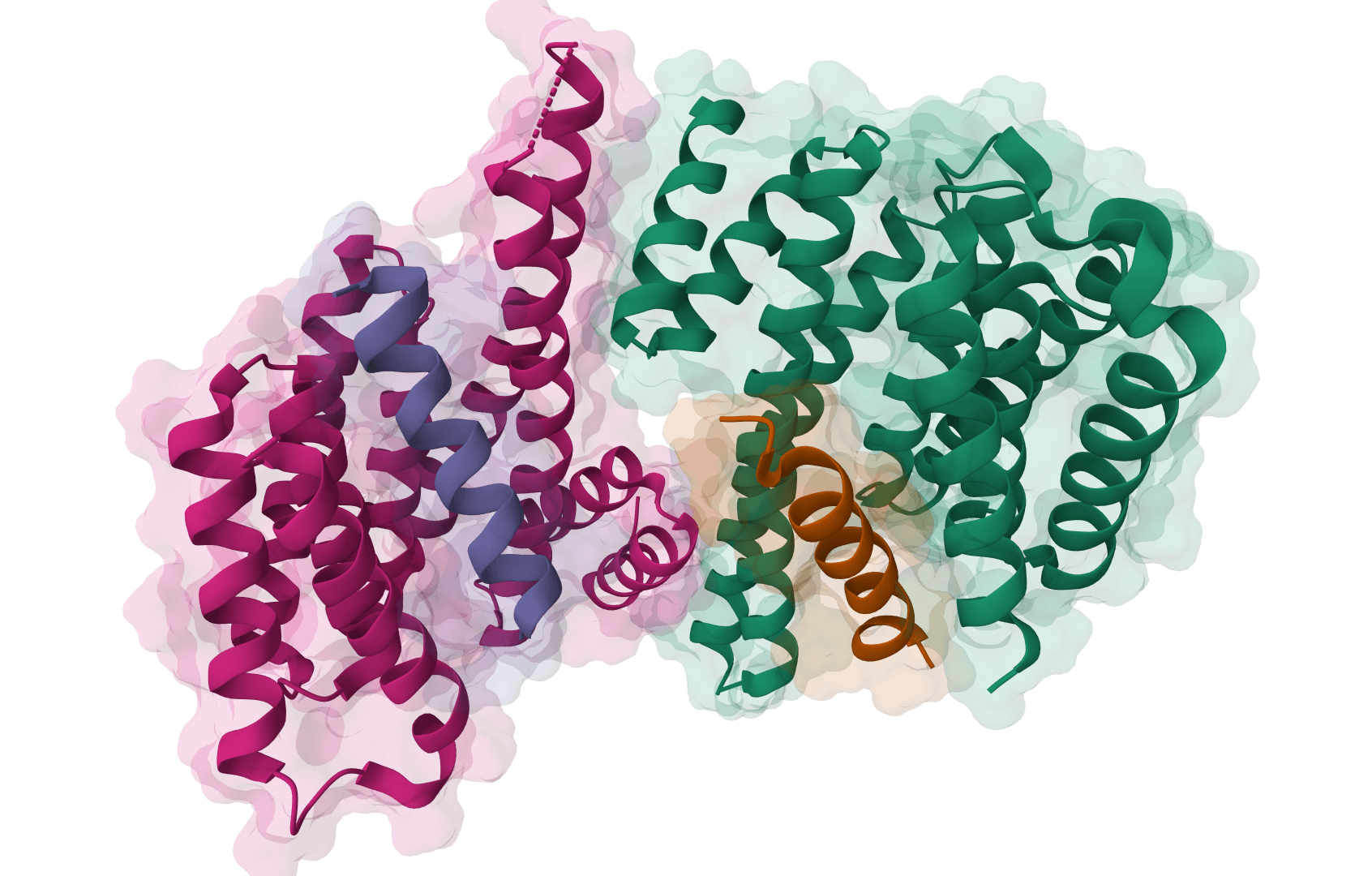
Design de novo protein binders using AlphaFold2 backpropagation, ProteinMPNN sequence optimization, and PyRosetta relaxation. BindCraft generates novel protein sequences that bind to user-specified target surfaces.
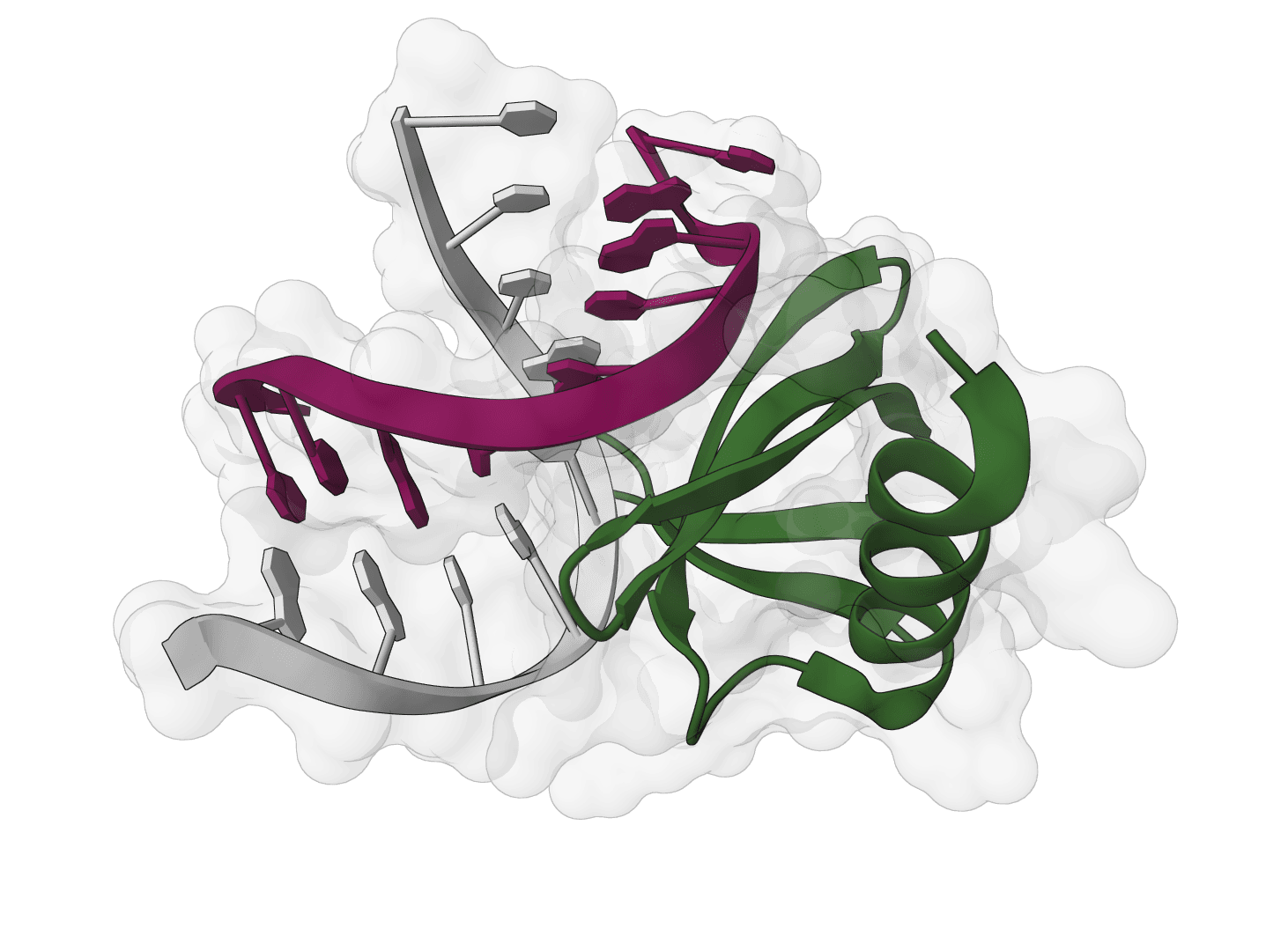
Optimize protein binders using genetic algorithms combined with AlphaFold2 fitness evaluation and ProteinMPNN sequence design. EvoPro evolves protein sequences to maximize binding affinity and structural quality through iterative cycles of mutation, selection, and validation.
mBER (Manifold Binder Engineering and Refinement) is an open-source computational framework for designing VHH nanobody binders that target specific protein surfaces. Developed by Manifold Bio and released in 2024, mBER uses AlphaFold-Multimer's structure prediction capabilities in reverse—optimizing antibody sequences until the model predicts confident binding to a target epitope. The system has demonstrated experimental success rates as high as 38% for certain targets, validated through million-scale screening experiments.
VHH nanobodies are single-domain antibodies derived from camelid heavy-chain-only antibodies, first discovered in 1989 by Professor Raymond Hamers at Vrije Universiteit Brussel. Unlike conventional antibodies that contain both heavy and light chains, VHH domains consist of a single variable domain (12–14 kDa, approximately one-tenth the size of traditional antibodies). VHH nanobodies offer therapeutic advantages including higher solubility, thermal stability, tissue penetration, and lower production costs. The FDA has approved several nanobody therapeutics, including Caplacizumab for blood disorders (2019) and CARVYKTI for multiple myeloma.
ProteinIQ provides a web-based interface for running mBER without GPU infrastructure or command-line installation. Upload a target protein structure, specify binding regions, adjust design parameters, and receive ranked VHH designs with 3D visualization.
| Input | Description |
|---|---|
Target Protein | The protein structure to design binders against. Upload a PDB file, enter a 4-character PDB ID (for example 7BZ5) to fetch from RCSB, or enter a UniProt accession (for example P0DTC2) to fetch the AlphaFold DB structure. The structure should include all chains relevant for binding analysis. |
| Setting | Description |
|---|---|
Target name | Optional native target name. Leave empty to let ProteinIQ derive it from the uploaded filename, PDB ID, or UniProt accession. |
Target chains | Chain identifier(s) from the PDB file to design binders against (default: A). For multi-chain targets, use comma separation (e.g., A,B). mBER will design nanobodies targeting the specified chains. |
Hotspot residues | Optional comma-separated list of specific residues to focus binding interactions. Format: ChainResidue (e.g., A56,A60,B23). When specified, mBER biases designs toward these positions. Leave empty for automatic epitope selection based on surface accessibility and geometry. |
| Setting | Description |
|---|---|
Number of designs | Number of accepted VHH sequences to generate (default 1 on ProteinIQ). Each design represents a unique nanobody sequence predicted to bind the target. Higher values provide more candidates and may require reserving more credits. |
Maximum trajectories | Maximum number of mBER design trajectories to attempt (default 10000). The run stops when this cap is reached, when the requested number of accepted designs is found, or when the reserved credit budget is reached. |
| Setting | Description |
|---|---|
Minimum iPTM | Minimum interface predicted template modeling score (0.50–0.95, default 0.75). iPTM specifically measures AlphaFold's confidence in the protein-protein interface geometry. Values above 0.75 indicate high-confidence binding interfaces; above 0.85 suggests exceptional quality. Lowering this threshold accepts more designs but may include weaker binders. |
Minimum pLDDT | Minimum predicted local distance difference test score (0.50–0.95, default 0.70). pLDDT measures per-residue structural confidence on a 0–1 scale. Values above 0.70 indicate well-structured regions; above 0.90 suggests near-atomic accuracy. Lower thresholds may accept designs with flexible or disordered regions. |
| Setting | Description |
|---|---|
Masked VHH framework | Optional binder.masked_sequence override. Use * at positions that mBER should redesign. Leave empty to use the default masked VHH framework. |
Skip trajectory animations | Passes the --no-animations behavior through the generated settings file to reduce output size. |
Skip pickle state files | Passes the --no-pickle behavior through the generated settings file to reduce output size. |
Skip PNG plots | Passes the --no-png behavior through the generated settings file to reduce output size. |
The output consists of accepted VHH nanobody designs in native acceptance order, plus the native artifact files produced for those accepted trajectories. ProteinIQ keeps the shared 3D viewer, spreadsheet, and file list, but the identifiers and filenames now stay aligned with native mBER rather than being re-ranked by the tool.
A run can also finish with no accepted designs. This is still a valid native mBER outcome when the reserved credit budget or trajectory cap is reached before any trajectory passes the configured iPTM and pLDDT thresholds. In that case, try reserving more credits, increasing maximum trajectories, lowering thresholds for exploratory runs, or adding hotspot residues if you know the target epitope.
| Column | Description |
|---|---|
Trajectory | native trajectory name for the accepted design. |
Binder | native binder index within that trajectory. |
Sequence | Accepted VHH amino acid sequence from accepted.csv. |
iPTM | Interface predicted TM score (0–1). Measures AlphaFold's confidence in the protein-protein interface. Higher values indicate more confident binding predictions. |
pLDDT | Predicted local distance difference test score (0–1). Measures overall structural confidence. Higher values indicate more accurate structure predictions. |
pTM | Predicted template modeling score (0–1). Measures global structural confidence of the entire complex. |
PAE / Interface PAE | Predicted aligned error metrics recovered from the per-trajectory evaluation data when available. Lower values indicate more confident geometry. |
Seq Entropy / ESM Score | Additional native evaluation metrics recovered from the retained trajectory data when available. |
Complex PDB / Relaxed PDB / Monomer PDB | native filenames for the accepted binder structures. Relaxed structures are shown when available; monomer structures come from the per-trajectory evaluation outputs. |
ProteinIQ returns the accepted-design artifact set for each accepted trajectory, including:
accepted.csviPTM (interface prediction)
pLDDT (structure quality)
Designs with both high iPTM (> 0.75) and high pLDDT (> 0.70) have the greatest likelihood of experimental success. Manifold Bio's validation experiments demonstrated per-binder success rates up to 38% for optimized epitopes.
mBER employs gradient-based optimization through AlphaFold-Multimer, effectively "hallucinating" nanobody sequences that fold into favorable binding configurations with target proteins. The approach inverts the traditional protein folding problem: instead of predicting structure from sequence, mBER optimizes sequences to achieve desired structural interactions.
mBER leverages AlphaFold-Multimer as a differentiable scoring function. The algorithm initializes a random VHH sequence, combines it with the target protein structure, and runs AlphaFold-Multimer to predict the complex structure. By backpropagating gradients through the neural network, mBER updates the sequence to maximize binding interface confidence metrics (iPTM) and structural quality (pLDDT).
The system builds upon the ColabDesign framework, which pioneered backpropagation-based protein design through structure prediction models. mBER extends this approach with nanobody-specific templates and sequence constraints.
To ensure designs adopt authentic nanobody architecture, mBER bases sequence generation on VHH structural templates. The framework uses NanoBodyBuilder2 to construct initial nanobody structures from template sequences. These templates enforce the characteristic immunoglobulin fold while allowing complementarity-determining region (CDR) loops to vary for target binding.
The CDR3 loop, which forms the primary antigen-binding surface in VHH nanobodies, receives particular attention during optimization. mBER allows this region to explore diverse conformations while maintaining structurally plausible geometries.
To bias designs toward naturally occurring antibody sequences, mBER incorporates ESM-2, a protein language model trained on millions of protein sequences. ESM-2 generates position-specific amino acid probabilities for masked regions of the VHH framework. These probabilities are converted to logits and sampled to produce sequences that resemble human antibody repertoires.
This dual conditioning—structural templates for geometry and sequence priors for naturalness—helps mBER avoid generating antibodies with unusual or developability-limiting sequences while exploring the design space for target-specific binding.
mBER generates multiple design trajectories in parallel, each starting from different random initializations. The algorithm runs optimization for a fixed number of iterations per trajectory, evaluating iPTM and pLDDT at each step. Trajectories that fail to meet minimum quality thresholds are discarded; successful trajectories contribute designs to the final output.
ProteinIQ bills mBER by reserved credits at 60 credits per compute minute. The default reservation is 7200 credits, which gives a 2-hour runtime budget; reserving 1800 credits gives 30 minutes. Unused reserved credits are refunded if mBER finishes because it found enough accepted designs or reached the maximum trajectory count. Challenging targets (buried epitopes, constrained surfaces, or strict quality thresholds) may consume the full reserved budget without producing accepted designs.
When specific residues are designated as hotspots, mBER biases the optimization to favor interactions with those positions. The algorithm increases weighting for inter-residue contacts between VHH CDR regions and hotspot residues, guiding designs toward epitope-specific binding modes.
Hotspot specification enables rational design based on prior experimental data (mutagenesis studies, known binding sites) or computational predictions (conservation analysis, druggability assessments). This feature distinguishes mBER from purely de novo approaches that lack epitope control.