Input
400 credits
Output
Configure input settings on the left, then click "Submit job"
Design de novo protein binders using AlphaFold2 backpropagation, ProteinMPNN sequence optimization, and PyRosetta relaxation. BindCraft generates novel protein sequences that bind to user-specified target surfaces.
Design linear peptide binders for target proteins using a target sequence-conditioned masked language model. PepMLM generates peptide sequences optimized to bind specific protein targets based on ESM-2 protein language modeling.
BoltzGen is a state-of-the-art AI model for designing protein and peptide binders against any biomolecular target. Using generative diffusion models, it creates novel binders (proteins, peptides, nanobodies) with nanomolar-level binding affinity.
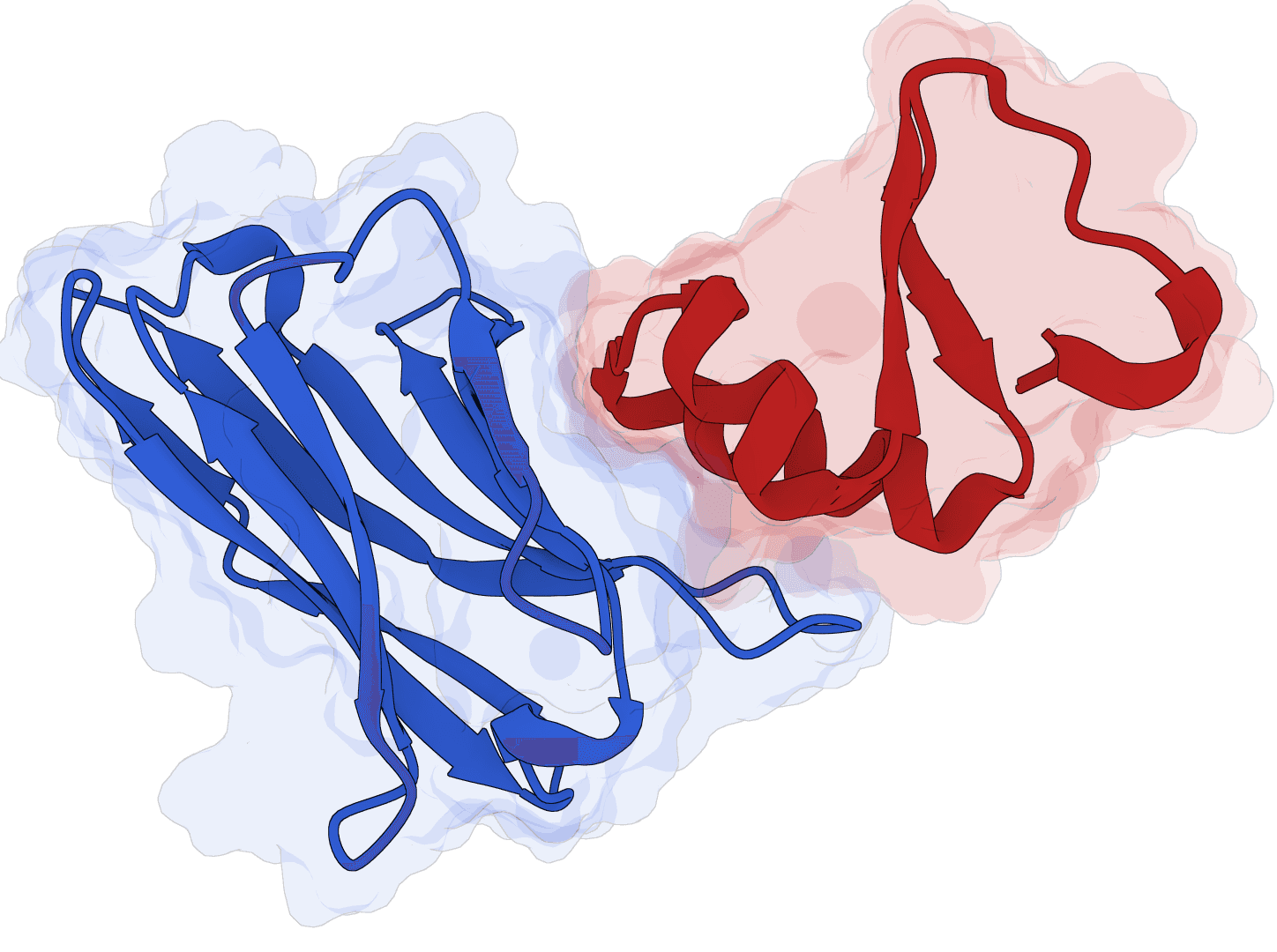
Design VHH nanobody binders using AlphaFold-Multimer with structure templates and sequence conditioning. mBER (Manifold Binder Engineering and Refinement) generates novel VHH antibody sequences that bind to user-specified target proteins.
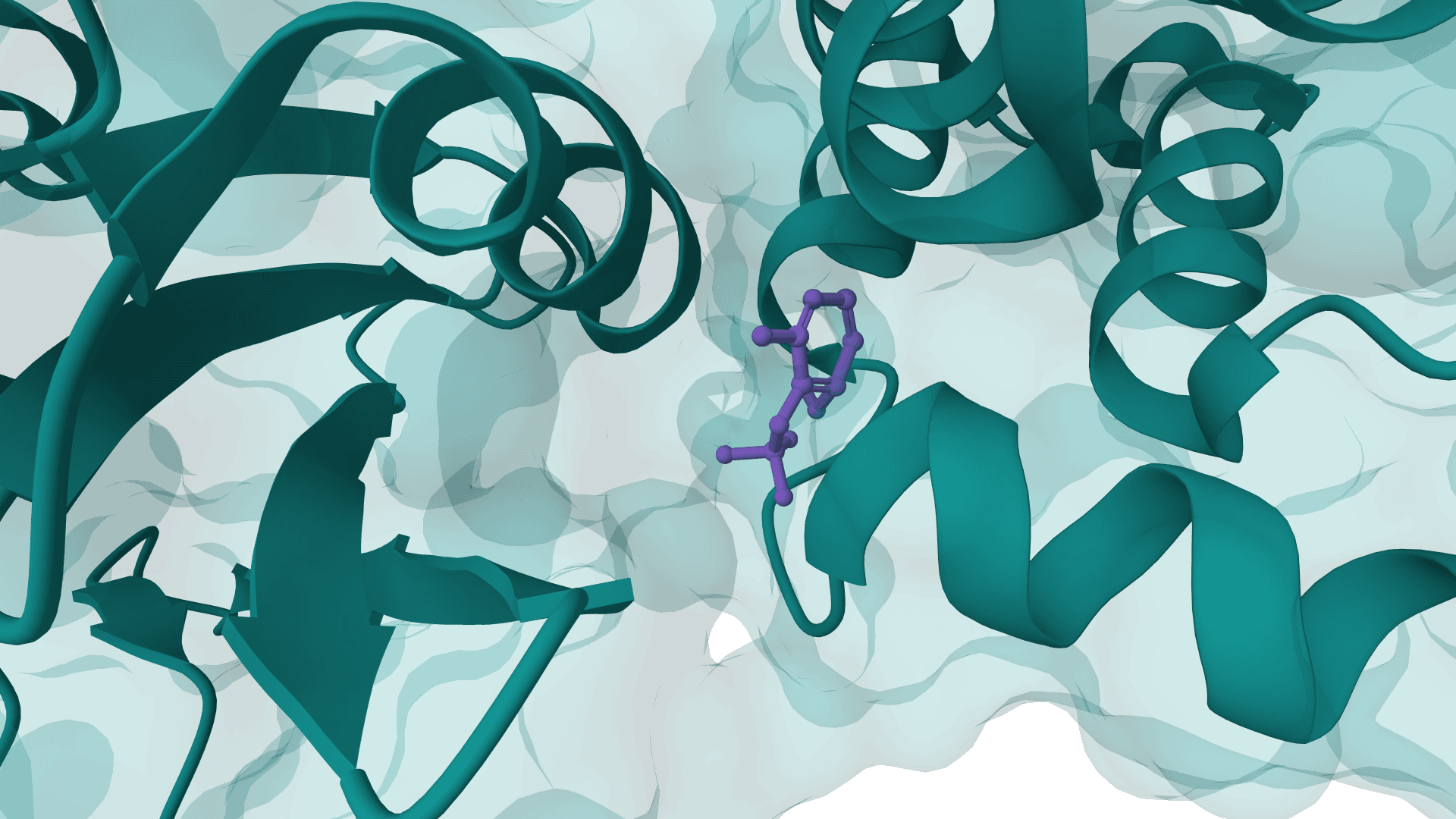
PocketFlow is a structure-based molecular generative model that designs novel drug-like molecules within protein binding pockets. It uses autoregressive flow modeling with chemical knowledge to generate 100% chemically valid, highly drug-like compounds.

PocketXMol is a pocket-interacting generative foundation model for docking, small-molecule design, and peptide design in protein binding pockets.
ProFam-1 is a protein family language model for family-conditioned sequence generation. Provide a protein family FASTA/MSA and generate new sequences with model likelihood scores for downstream ranking and screening.
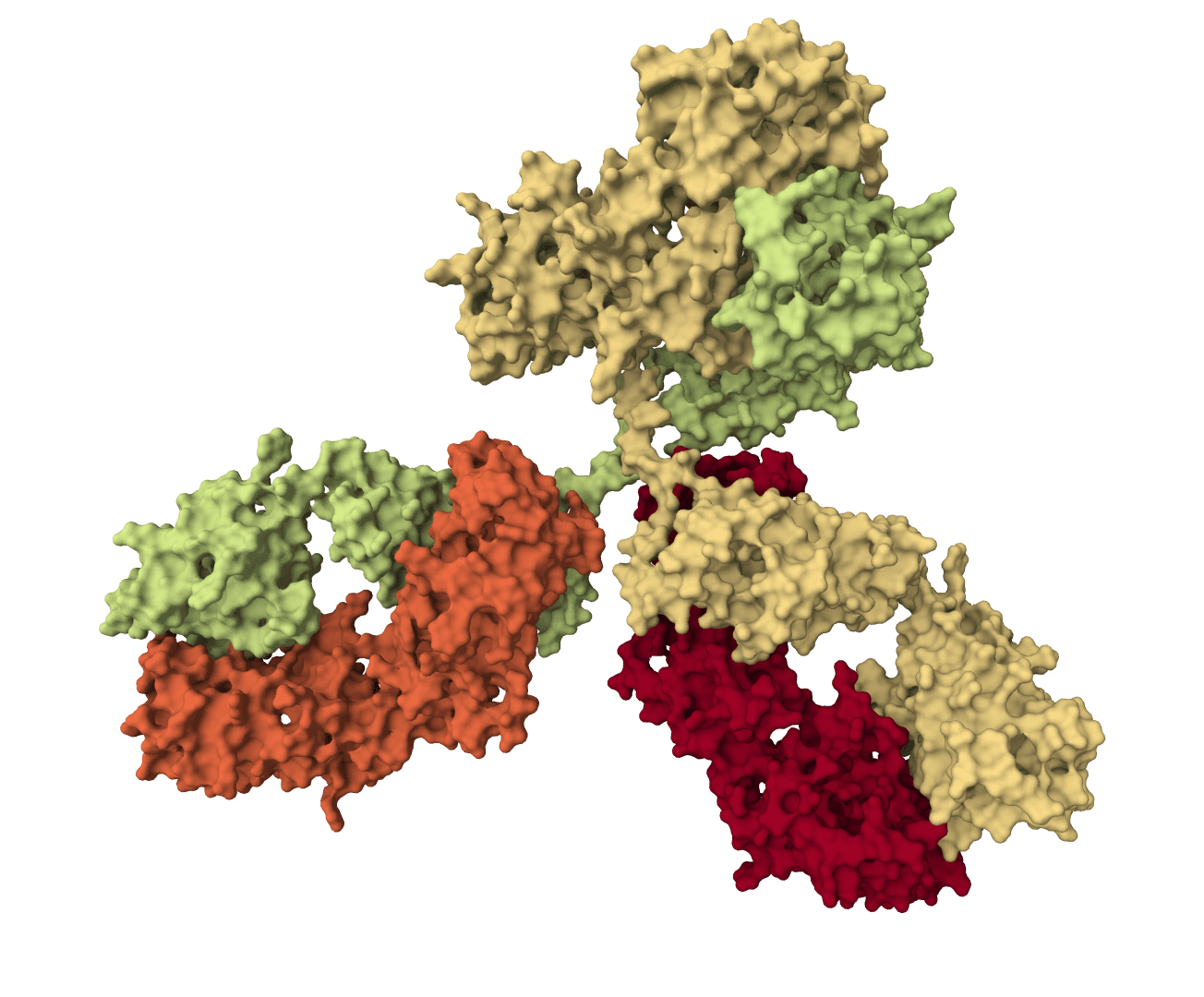
Reasoning-guided antibody CDR co-design for antibody-antigen complexes. Proteo-R1 identifies residue-level functional decisions and uses conditional diffusion to generate ranked designed structures with confidence metrics.
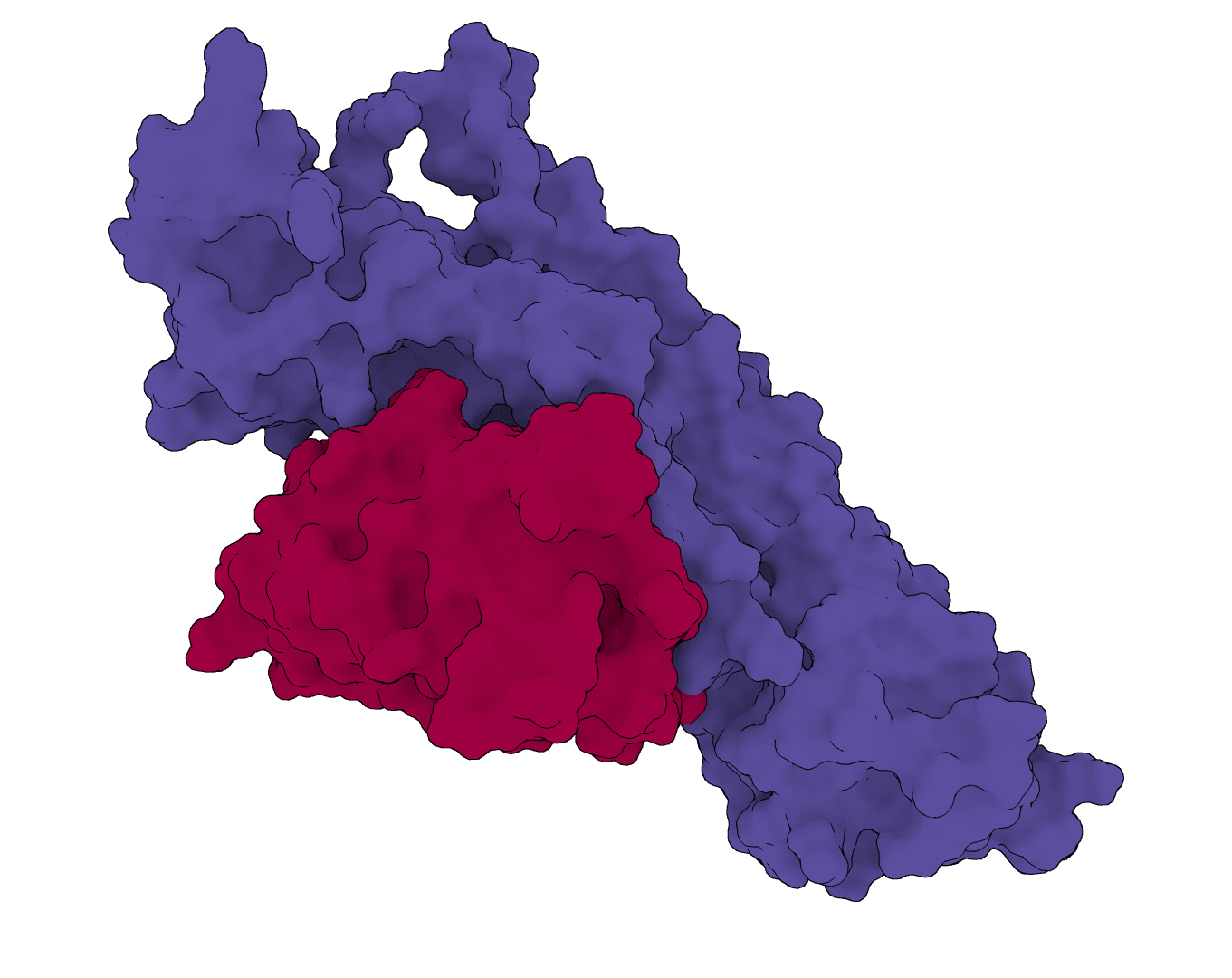
Structure-based de novo antibody and nanobody design pipeline combining antibody-tuned RFdiffusion, ProteinMPNN sequence design, and antibody-tuned RoseTTAFold2 filtering.
Inverse folding with ESM-IF1. Design protein sequences for given 3D backbone structures using a geometric deep learning model. Generate multiple sequence variants optimized for your target structure.
EvoPro is a genetic algorithm-based pipeline for designing protein binders through in silico evolution. Developed by the Kuhlman Lab at the University of North Carolina, it combines iterative structure prediction with AlphaFold2 and sequence design with ProteinMPNN to evolve protein sequences that bind tightly to a target protein.
The approach differs from traditional computational design methods by allowing backbone plasticity during optimization. As sequences evolve across generations, their predicted structures can undergo conformational changes favorable for binding—something difficult to encode in physics-based design methods like Rosetta.
In published work, EvoPro generated autoinhibitory domains for a PD-L1 antagonist, with four designs achieving sub-150 nM binding affinity and the best reaching 0.9 nM without any experimental optimization.
EvoPro runs a genetic algorithm that maintains a population of candidate binder sequences and evolves them through repeated cycles:
The fitness score combines three components from AlphaFold2 predictions:
| Component | What it measures |
|---|---|
| Placement confidence | Interface quality based on sidechain contacts weighted by PAE (predicted aligned error) |
| Fold confidence | Binder stability from average pLDDT across the designed protein |
| Conformational stability | RMSD between bound and unbound structures to minimize binding-induced changes |
Lower scores indicate better designs. The conformational stability term encourages rigid binders with fast association kinetics.
New sequences are generated through two strategies:
ProteinIQ provides GPU-accelerated EvoPro runs without local installation, making binder design accessible through a browser interface.
| Input | Description |
|---|---|
Target Protein | PDB file or RCSB PDB ID for the protein to design binders against |
Starting Scaffold | Optional starting structure or sequence. If omitted, EvoPro generates scaffolds automatically |
| Setting | Range | Default | Description |
|---|---|---|---|
Population size | 20–500 | 100 | Candidates per generation. Larger populations explore more diversity but increase runtime |
Number of generations | 5–200 | 50 | Evolutionary cycles. More generations improve optimization at the cost of time |
Mutation rate | 0.05–0.5 | 0.15 | Per-residue mutation probability. Higher rates increase diversity but may slow convergence |
| Setting | Description |
|---|---|
Mutable residues | Restrict which positions can mutate. Use A* for all residues in chain A, or specify positions like A10,A15,A20. Leave empty to allow all positions |
Enable ProteinMPNN | Toggle ProteinMPNN sequence design during evolution (recommended) |
| Setting | Range | Default | Description |
|---|---|---|---|
pLDDT threshold | 50–95 | 70 | Minimum structure confidence. Higher values filter to more confident predictions |
PAE threshold | 5–30 | 15 | Maximum interface error. Lower values require higher confidence in the binding interface |
EvoPro returns a ranked list of designed binders with:
| Column | Description |
|---|---|
Rank | Position in the ranked output (1 = best) |
Binding Score | Composite fitness score (lower = better) |
pLDDT | Average structure confidence (0–100) |
Sequence | Designed amino acid sequence |
Download | PDB file of the predicted complex |
The 3D viewer displays selected designs bound to the target protein.
| Score range | Interpretation |
|---|---|
| < -50 | Excellent candidate, high confidence interface |
| -50 to -30 | Good candidate, worth experimental validation |
| -30 to -10 | Moderate, may require optimization |
| > -10 | Weak prediction, likely needs redesign |
Scores depend heavily on target protein and starting scaffolds. Compare designs relative to each other rather than using absolute thresholds.