Input
5 credits
Output
Configure input settings on the left, then click "Run IgBLAST"
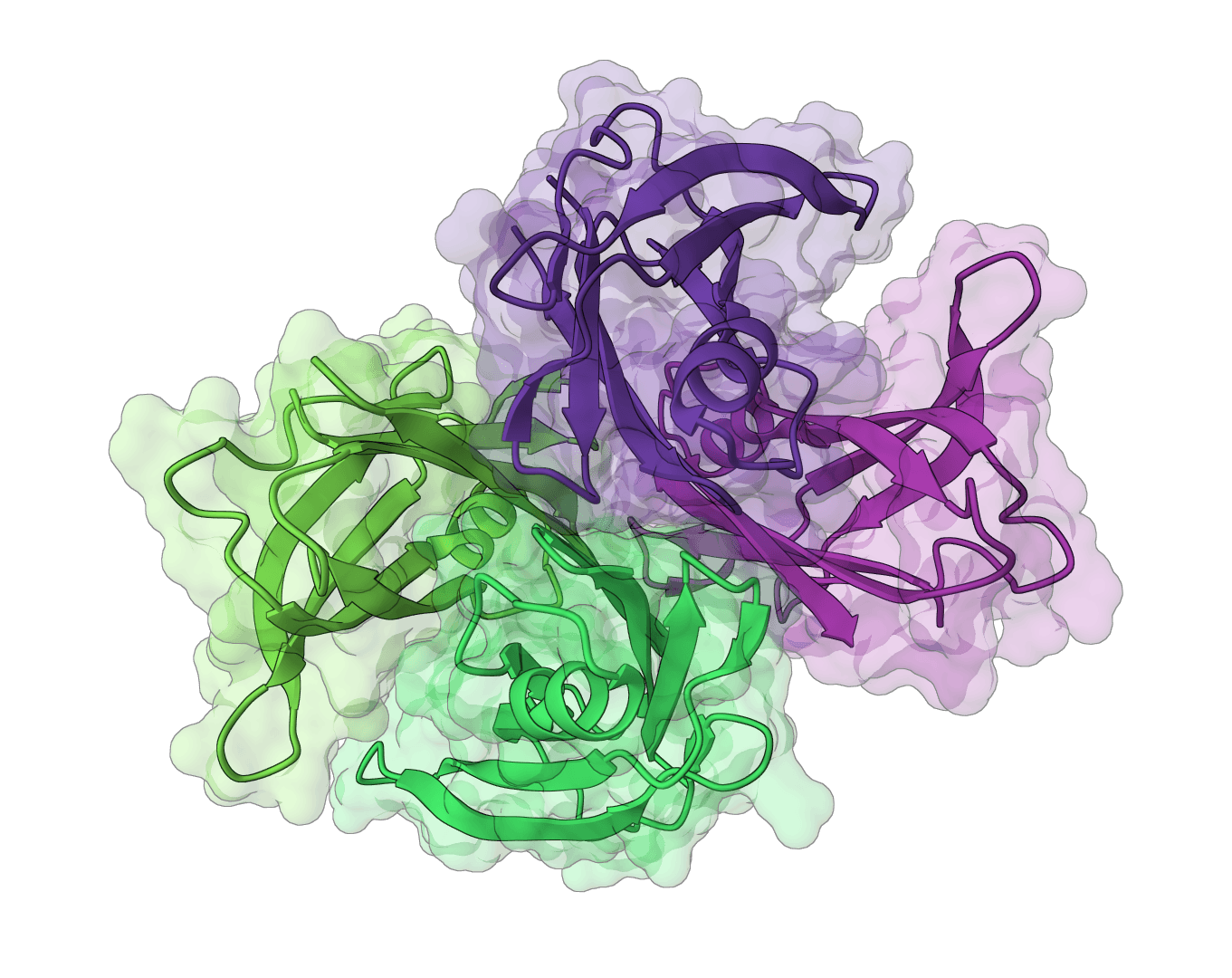
Number antibody and T cell receptor variable domain sequences using multiple numbering schemes (IMGT, Chothia, Kabat, Martin, AHo, Wolfguy). Identifies chain type, species, and assigns germline genes.
Sensitive sequence homology search using profile hidden Markov models. More accurate than BLAST for detecting remote homologs, ideal for finding evolutionarily distant protein family members.
Perform multiple sequence alignment using MAFFT (Multiple Alignment using Fast Fourier Transform). Supports multiple algorithms from fast progressive to highly accurate iterative methods.
Ultra-fast sequence search and clustering. 10,000x faster than BLAST for database searches, with powerful sequence clustering capabilities for proteins and nucleotides.
Perform multiple sequence alignment using MUSCLE5 (MUltiple Sequence Comparison by Log-Expectation). Uses the PPP algorithm for high-quality alignments with support for ensemble generation.
Fast protein structure search, comparison, and clustering. Search your structure against 200M+ AlphaFold predictions, compare 2 structures, or cluster up to 2500.
USAlign (Universal Structure Alignment) aligns protein, RNA, and DNA structures to compute TM-scores and generate superposed structures. Compare 3D structures to assess structural similarity.
Rapidly align and compare DNA sequences using MUMmer4 nucmer. Perform pairwise genome comparisons to identify SNPs, indels, and structural variants between reference and query genomes.
Perform multiple sequence alignment on protein or nucleotide sequences using the Clustal Omega algorithm.
Infer approximately-maximum-likelihood phylogenetic trees from alignments of nucleotide or protein sequences.
IgBLAST (Immunoglobulin BLAST) is a specialized sequence analysis tool designed to analyze immunoglobulin (antibody) and T cell receptor variable domain sequences. Developed by researchers at the National Center for Biotechnology Information (NCBI), IgBLAST automates the identification of V (Variable), D (Diversity), and J (Joining) gene segments, delineates complementarity determining regions (CDRs), and analyzes rearrangement junctions in antigen receptor sequences.
The tool was published in 2013 in Nucleic Acids Research by Jian Ye, Ning Ma, Thomas L. Madden, and James M. Ostell to address limitations of general-purpose sequence alignment tools like standard BLAST. Unlike conventional BLAST, which cannot efficiently handle the rearranged nature and variable segment lengths characteristic of immunoglobulin sequences, IgBLAST performs specialized sequential searches optimized for antibody and T cell receptor analysis.
The most common applications include
ProteinIQ provides a web-based interface for running IgBLAST without command-line installation or local database setup. Upload antibody or TCR sequences in FASTA format, configure organism and receptor settings, and receive comprehensive V/D/J gene assignments with CDR region annotations in a sortable spreadsheet format.
| Input | Description |
|---|---|
Antibody/TCR sequences | FASTA-formatted nucleotide or protein sequences from immunoglobulin or T cell receptor variable regions. Accepts batch submissions with multiple sequences. Maximum file size: 50 MB. |
| Setting | Description |
|---|---|
Organism | Species source of germline gene database. Options: Human (default), Mouse, Rabbit, Rat, Rhesus monkey. Selects appropriate V/D/J gene reference libraries. |
Receptor type | Antigen receptor class. Ig (immunoglobulin/antibody, default) or TCR (T cell receptor). Determines which gene segment databases are searched. |
Sequence type | Input sequence format. Auto-detect (default) determines whether sequences are nucleotide or protein based on character composition. Nucleotide (DNA/RNA) provides complete V/D/J analysis. Protein (amino acid) analyzes V gene only. |
| Setting | Description |
|---|---|
Database source | Reference germline gene library. IMGT (default, recommended) provides standardized international nomenclature. NCBI includes additional species coverage. |
Domain system | CDR numbering scheme. IMGT (default) is the international standard for antibody analysis. Kabat is an alternative legacy numbering system. |
| Setting | Description |
|---|---|
Max alignments per gene | Number of top-scoring V/D/J gene matches to report per sequence (1–10, default 3). Higher values reveal alternative gene assignments when sequences match multiple alleles. |
Show translation | Include amino acid translation for nucleotide input sequences (default enabled). |
The output consists of a spreadsheet with one row per analyzed sequence, showing gene segment assignments, identity scores, CDR3 sequences, and productivity status.
| Column | Description |
|---|---|
Query ID | Sequence identifier from FASTA header. |
Chain | Antibody or TCR chain classification. VH (heavy chain), VL-KAPPA (kappa light chain), VL-LAMBDA (lambda light chain), or TCR chains (VA, VB, VG, VD). |
V Gene | Variable gene segment assignment with allele designation (e.g., IGHV3-23*01). Multiple matches separated by commas indicate ambiguous assignments. |
V Identity % | Percentage sequence identity to assigned V gene germline sequence. Reflects degree of somatic hypermutation. |
D Gene | Diversity gene segment assignment (heavy chains and TCR beta/delta only). Light chains show N/A as they lack D segments. |
J Gene | Joining gene segment assignment. |
CDR3 (AA) | Complementarity determining region 3 amino acid sequence. The most variable antibody region responsible for antigen specificity. |
CDR3 (NT) | CDR3 nucleotide sequence. |
Junction | Complete nucleotide sequence spanning the V-D-J junction, including trimmed germline bases and non-templated insertions. |
Productive | Rearrangement functionality. Yes indicates in-frame junction without premature stop codons. No indicates non-functional rearrangement. |
V gene identity percentages reveal the extent of somatic hypermutation:
Lower identity scores suggest prolonged antigen-driven selection and affinity maturation.
CDR3 represents the antibody's primary antigen contact region and exhibits the highest sequence diversity due to junctional diversity during V(D)J recombination. The CDR3 amino acid sequence serves as a molecular fingerprint for clonal B cell populations. Identical CDR3 sequences across multiple antibodies indicate they likely originated from the same B cell ancestor.
D (Diversity) genes are particularly short (10–30 nucleotides) and undergo extensive nucleotide deletions and additions during recombination. Multiple D gene matches (e.g., IGHD3-10*01,IGHD3-10*02,IGHD3-16*01) indicate ambiguous assignments due to:
When multiple D genes are reported, the first listed represents the top-scoring match.
IgBLAST employs a specialized multi-stage BLAST search strategy with optimized parameters for each gene segment type, combined with biological constraint enforcement and automated CDR/framework region annotation.
Unlike standard BLAST which performs a single search, IgBLAST executes three sequential searches with segment-specific parameters:
After identifying the top V gene match, that region is masked before searching for D and J genes, preventing spurious alignments to the already-identified V segment.
IgBLAST applies immunological rules during analysis:
The tool maps complementarity determining regions (CDRs) and framework regions (FRs) by:
This automated annotation eliminates manual boundary identification required when using standard sequence alignment tools.
IgBLAST searches against curated germline gene databases containing:
The IMGT database provides standardized international nomenclature, while NCBI databases offer broader species coverage. Both databases undergo regular updates as new germline gene sequences are characterized.
Understanding V(D)J recombination is essential for interpreting IgBLAST results. During B cell and T cell development, developing lymphocytes undergo V(D)J recombination, a somatic DNA rearrangement process that generates antigen receptor diversity.
Immunoglobulin and TCR genes are organized as arrays of multiple gene segments in germline DNA:
Human immunoglobulin heavy chain loci contain approximately 50 functional V genes, 23 D genes, and 6 J genes, enabling combinatorial diversity.
During lymphocyte development:
This process creates a continuous coding sequence for the antibody variable region.
Additional diversity is generated at V-D-J junctions through:
These modifications create the hypervariable CDR3 region, which IgBLAST identifies in the junction analysis.
After initial V(D)J recombination, activated B cells undergo somatic hypermutation in germinal centers, introducing point mutations into V region genes. This process enables affinity maturation—progressive improvement of antibody binding affinity through iterative mutation and antigen-driven selection. The V gene identity percentage reported by IgBLAST directly reflects the extent of somatic hypermutation.