Input
5 credits
Output
Configure input settings on the left, then click "Submit job"
Humatch is an antibody humanization tool that transforms non-human antibody sequences into humanized variants. Uses three lightweight CNNs to identify optimal human V-genes and generate paired heavy and light chain sequences with minimal edits while maintaining functionality.
Reasoning-guided antibody CDR co-design for antibody-antigen complexes. Proteo-R1 identifies residue-level functional decisions and uses conditional diffusion to generate ranked designed structures with confidence metrics.
Structure-based de novo antibody and nanobody design pipeline combining antibody-tuned RFdiffusion, ProteinMPNN sequence design, and antibody-tuned RoseTTAFold2 filtering.
Inverse folding for antibody variable domains and nanobodies. Predicts amino acid sequences compatible with antibody structures using IMGT numbering while preserving native AntiFold chain handling and structural constraints.
Antibody humanization and humanness evaluation platform from Merck. Sapiens mode uses deep learning trained on the Observed Antibody Space (OAS) to humanize antibody sequences, while OASis mode evaluates humanness using 9-mer peptide search against human antibody databases.
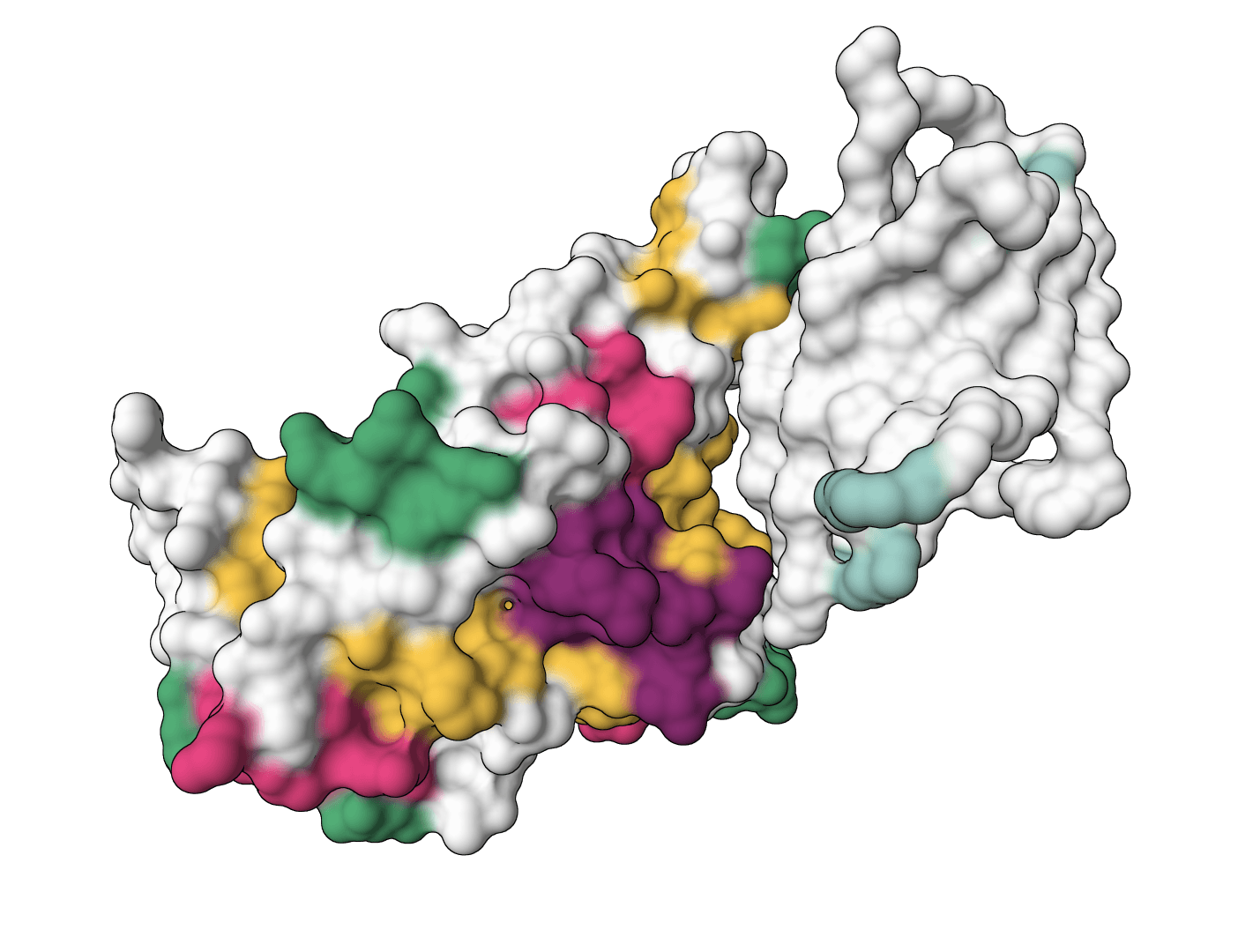
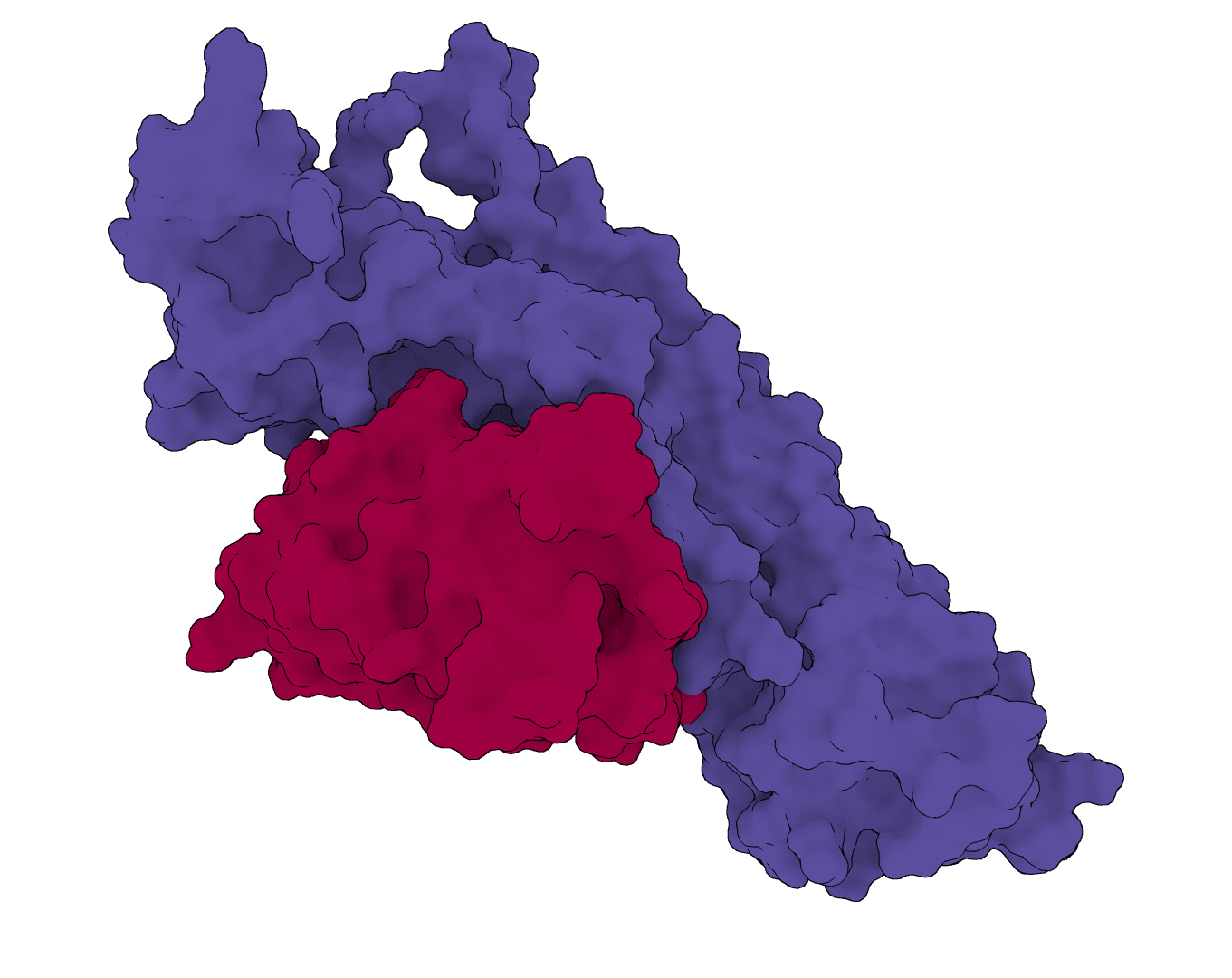
Design antibody CDR sequences via inverse folding. Generates complementarity-determining region (CDR) sequences for antibodies targeting therapeutic antigens using deep learning. Optimizes CDR loops (HCDR1, HCDR2, HCDR3) based on antibody-antigen complex structures.
Design VHH nanobody binders using AlphaFold-Multimer with structure templates and sequence conditioning. mBER (Manifold Binder Engineering and Refinement) generates novel VHH antibody sequences that bind to user-specified target proteins.
AI-powered antibody CDR design using equivariant diffusion models. Generates optimized complementarity-determining region (CDR) sequences and structures for antibodies targeting specific antigens. Supports single CDR, multi-CDR co-design, and fixed-backbone sequence design modes.
BoltzGen is a state-of-the-art AI model for designing protein and peptide binders against any biomolecular target. Using generative diffusion models, it creates novel binders (proteins, peptides, nanobodies) with nanomolar-level binding affinity.
EvoDiff is a diffusion-based protein sequence generation framework from Microsoft Research. ProteinIQ currently wraps the EvoDiff-Seq OA_DM_38M model for unconditional protein generation, motif scaffolding, and user-sequence inpainting.
IgGM (Immunoglobulin Generative Model) is a generative foundation model for designing antibodies and nanobodies against target antigens. Developed by Tencent AI4S and published at ICLR 2025, it can generate sequence proposals and, for some tasks, structural outputs as well.
The model excels at designing complementarity-determining regions (CDRs), the hypervariable loops responsible for antigen recognition. On benchmark tests, IgGM achieved a 36% sequence recovery rate for CDR-H3 (the most flexible and challenging region), representing a 22% improvement over prior state-of-the-art methods.
IgGM supports both conventional antibodies (heavy + light chain) and single-domain nanobodies. It won a top-three prize in the AIntibody competition, an experimentally validated antibody design challenge.
IgGM combines three components:
Training proceeds in two phases. First, a diffusion model learns structure prediction while preserving original sequence information. Then a consistency model is distilled from the diffusion model, enabling fast generation from arbitrary noise levels. This two-phase approach proved essential for model performance.
ProteinIQ provides GPU-accelerated IgGM without local installation or the complexity of managing PyTorch Geometric dependencies.
| Input | Description |
|---|---|
Heavy Chain (VH) | Antibody heavy chain variable region sequence. Mark positions to design with X characters. |
Light Chain (VL) | Light chain variable region (optional for nanobodies). |
Antigen Structure | Required. PDB file of the target antigen. Upload directly or fetch by PDB ID. |
Antigen Sequence | Optional sequence for epitope-guided design. If omitted, extracted from PDB. |
Original Sequence | Reference sequence for affinity maturation comparisons. |
The X character indicates positions for the model to redesign. For CDR design, mask the CDR residues while providing the framework sequence.
| Task | Description |
|---|---|
CDR Design | Design CDR loops to bind the target epitope. Provide framework sequence with X at CDR positions. |
Inverse Design | Generate a sequence compatible with an existing antibody structure. |
Framework Design | Redesign framework regions while preserving CDRs. Useful for humanization. |
Affinity Maturation | Optimize an existing antibody for improved binding. Provide original sequence for comparison. |
| Setting | Description |
|---|---|
Number of designs | Samples to generate (1–100, default 10). More samples provide diversity but increase runtime. |
Epitope residues | Target binding site positions on the antigen (e.g., 45,46,47,50-55). If omitted, calculated automatically from the antigen structure. |
Apply PyRosetta relaxation | Energy minimization to improve structural quality. Increases runtime. |
Random seed | For reproducible results. Leave empty for random seed. |
IgGM can produce:
Sequence-only and epitope-only runs are shown in task-appropriate result tabs instead of the 3D viewer. All emitted files remain downloadable as a ZIP archive.
The epitope—the antigen region the antibody should bind—guides design. IgGM requires epitope information and handles it three ways:
417,449,453,455-456). Numbers correspond to sequence positions, not PDB residue IDs.Epitope size is limited to 50 residues to manage computational cost.
max_antigen_size parameter, 2000 residues by default in ProteinIQ unless overridden).