Input
100 credits
Output
Configure input settings on the left, then click "Submit job"
Inverse folding for antibody variable domains and nanobodies. Predicts amino acid sequences compatible with antibody structures using IMGT numbering while preserving native AntiFold chain handling and structural constraints.
Design thermostable protein sequences using ProteinMPNN trained on hyperthermophilic organism structures. Generates sequences optimized for improved thermal stability without requiring ligands or additional context.
Design protein sequences with atomic context from ligands, metals, and nucleotides. Achieves 63.3% sequence recovery at binding sites, significantly outperforming ProteinMPNN (50.5%).
Design protein sequences for given backbone structures using deep learning. Fast and accurate inverse folding with state-of-the-art sequence recovery (52.4%).
Specialized model for soluble protein sequence design. Trained exclusively on soluble proteins for optimized performance on cytoplasmic and extracellular proteins.
Humatch is an antibody humanization tool that transforms non-human antibody sequences into humanized variants. Uses three lightweight CNNs to identify optimal human V-genes and generate paired heavy and light chain sequences with minimal edits while maintaining functionality.
Design VHH nanobody binders using AlphaFold-Multimer with structure templates and sequence conditioning. mBER (Manifold Binder Engineering and Refinement) generates novel VHH antibody sequences that bind to user-specified target proteins.
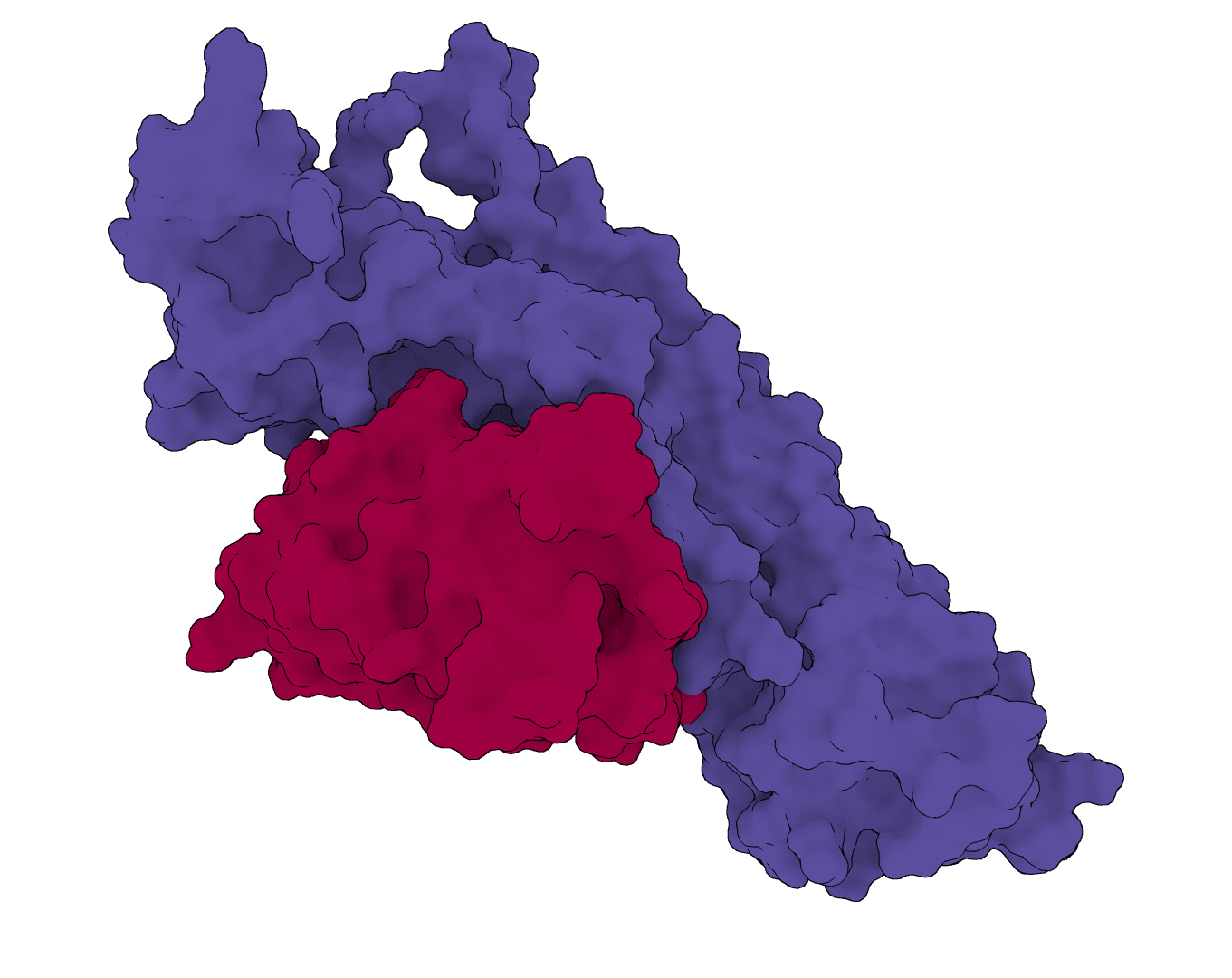
Structure-based de novo antibody and nanobody design pipeline combining antibody-tuned RFdiffusion, ProteinMPNN sequence design, and antibody-tuned RoseTTAFold2 filtering.
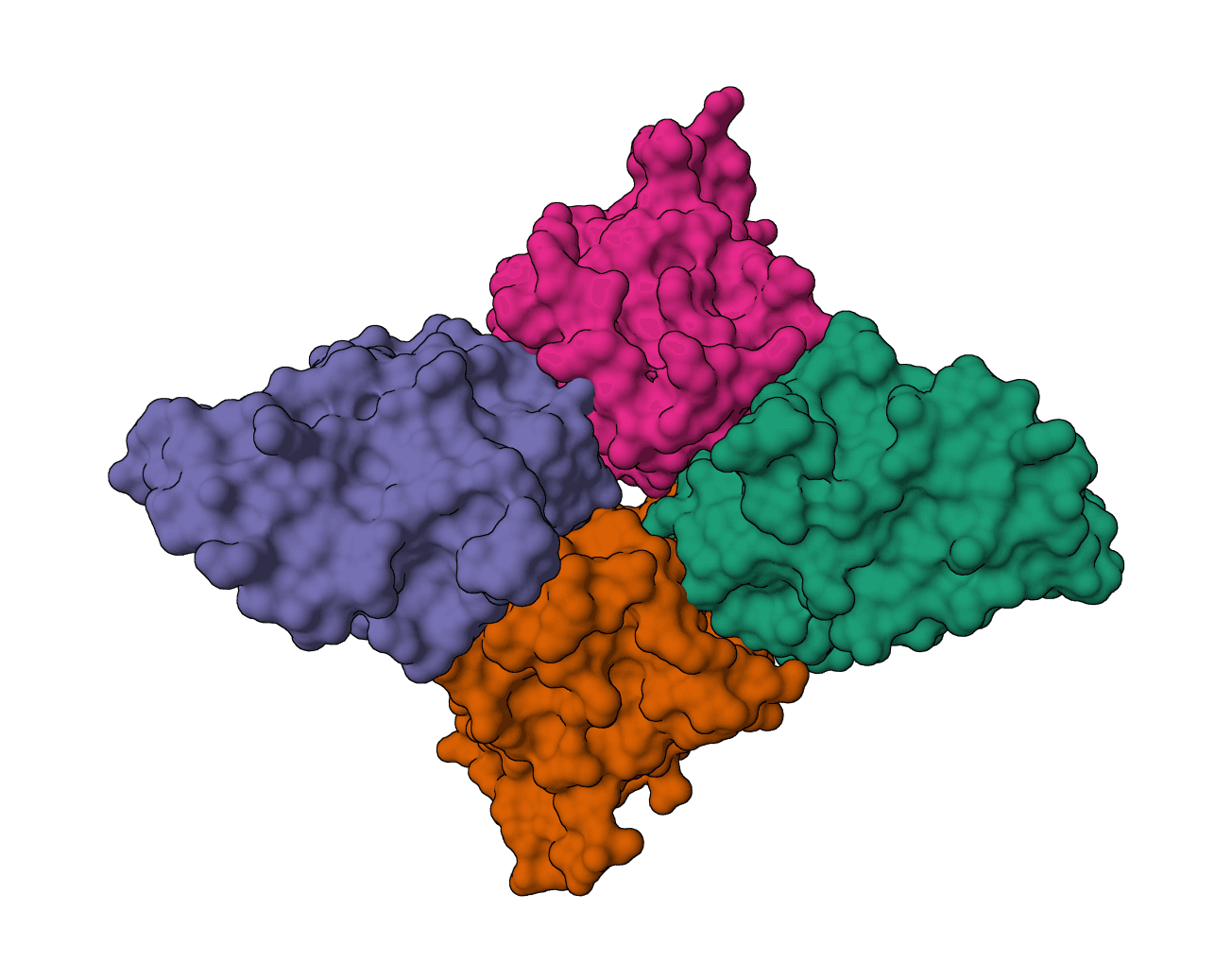
Antibody humanization and humanness evaluation platform from Merck. Sapiens mode uses deep learning trained on the Observed Antibody Space (OAS) to humanize antibody sequences, while OASis mode evaluates humanness using 9-mer peptide search against human antibody databases.
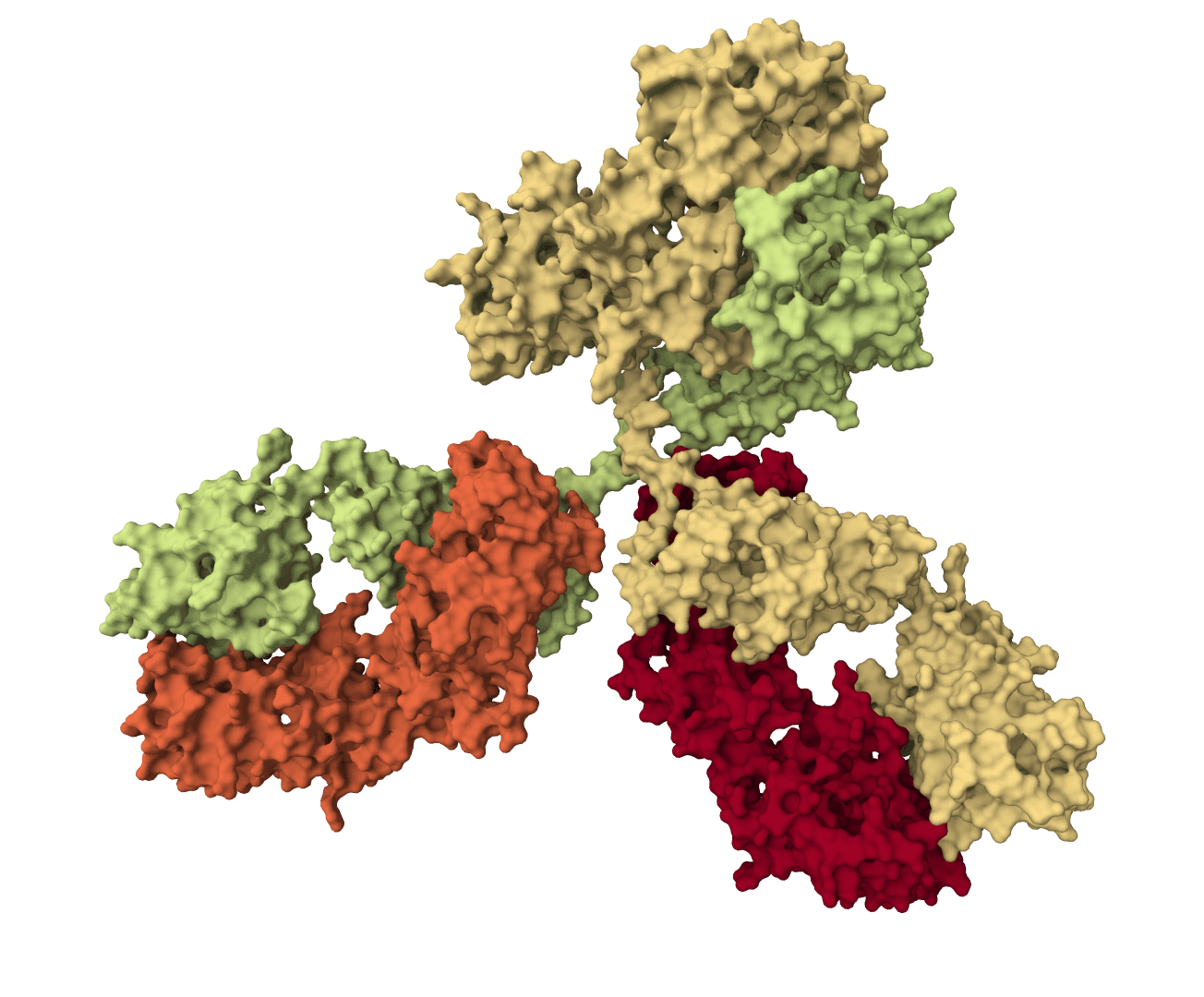
Reasoning-guided antibody CDR co-design for antibody-antigen complexes. Proteo-R1 identifies residue-level functional decisions and uses conditional diffusion to generate ranked designed structures with confidence metrics.
IgDesign is a deep learning model for designing antibody complementarity-determining region (CDR) sequences. Developed by Absci, it uses inverse folding—predicting amino acid sequences from backbone structures—to generate CDR variants that maintain structural compatibility with a target antigen.
The model was experimentally validated against eight therapeutic antigens, achieving successful binder design across multiple targets. In surface plasmon resonance (SPR) experiments, IgDesign-generated antibodies matched or exceeded the binding affinities of clinically validated reference antibodies for targets including CD40 and ACVR2B.
Inverse folding reverses the typical protein folding problem: instead of predicting structure from sequence, it predicts which sequences would fold into a given structure. For antibodies, this means generating CDR sequences compatible with a known antibody-antigen complex geometry.
IgDesign conditions on three sources of structural information:
The model was pre-trained on general protein structures, then fine-tuned specifically on antibody-antigen complexes from the Structural Antibody Database (SAbDab). Training used antigen holdouts at 40% sequence identity to prevent data leakage.
IgDesign generates CDR residues one position at a time, conditioning each prediction on previously generated residues. The design order (which CDR to generate first, second, third) affects the final sequences—the model explores multiple decoding orders and combines results.
ProteinIQ runs IgDesign on cloud GPUs, handling model setup and execution without requiring local installation.
| Input | Description |
|---|---|
Antibody-Antigen Complex | PDB structure file or RCSB PDB ID (e.g., 1N8Z). Must contain heavy chain, light chain, and antigen. |
| Setting | Description |
|---|---|
Heavy chain ID | Chain identifier for the antibody heavy chain (default H). Match the chain ID in the PDB file. |
Light chain ID | Chain identifier for the antibody light chain (default L). |
Antigen chain ID | Chain identifier for the antigen (default A). |
| Setting | Description |
|---|---|
CDR regions to design | Which heavy chain CDRs to redesign: HCDR1, HCDR2, HCDR3, or any combination. Default is all three. |
Number of sequences | Sequence variants to generate (1–100, default 10). More variants explore sequence space more thoroughly. |
Sampling temperature | Controls sequence diversity. Lower (0.1–0.5) produces conservative, high-confidence designs. Higher (1.0–2.0) generates more diverse sequences. Default 0.5. |
Results appear as a spreadsheet with one row per generated sequence variant. Columns include:
| Column | Description |
|---|---|
hcdr1, hcdr2, hcdr3 | Designed CDR sequences (for each region selected) |
ce_loss | Cross-entropy loss—lower values indicate higher model confidence that the sequence matches the structure |
The ce_loss column reflects how well the generated sequence fits the target backbone structure according to the model. Lower cross-entropy indicates higher confidence. However, low loss does not guarantee binding—experimental validation is always required.
Typical values vary by target complexity:
| CE loss | Interpretation |
|---|---|
| < 1.0 | High confidence design |
| 1.0–2.0 | Moderate confidence |
| > 2.0 | Lower confidence, consider adjusting temperature or target structure |
Rank sequences by cross-entropy loss when prioritizing candidates for experimental testing. Consider testing multiple sequences across the confidence range—sometimes higher-diversity sequences (higher temperature) discover unexpected solutions.