Input
3 credits
Output
Configure input settings on the left, then click "Submit job"
Predict ADMET (Absorption, Distribution, Metabolism, Excretion, Toxicity) properties from SMILES strings using machine learning models trained on Therapeutics Data Commons datasets.
Predict 22 ADMET properties from SMILES strings with the native Admetica Chemprop models from Datagrok.

Identify toxic, reactive, and pharmacokinetically problematic molecular fragments using structural alert patterns
Screen for lead-like compounds using stricter molecular descriptor criteria than Lipinski or Veber rules for early-stage drug discovery
Screen compounds for Pan-Assay Interference patterns that cause false positives in biological assays
Quantitative estimate for protein-protein interaction inhibitor potential. Evaluates drug-likeness for compounds targeting PPIs.
Screen compounds for structural toxicity alerts using PAINS, Brenk, and NIH filters. For focused screening, see PAINS Filter, Brenk Filter, or Veber's Rule.
Veber's Rule predicts oral bioavailability by evaluating molecular weight, LogP, hydrogen bond donors/acceptors, and rotatable bonds
Lipinski's Rule of Five predicts whether compounds will be orally bioavailable by evaluating molecular weight, LogP, hydrogen bond donors, and acceptors.
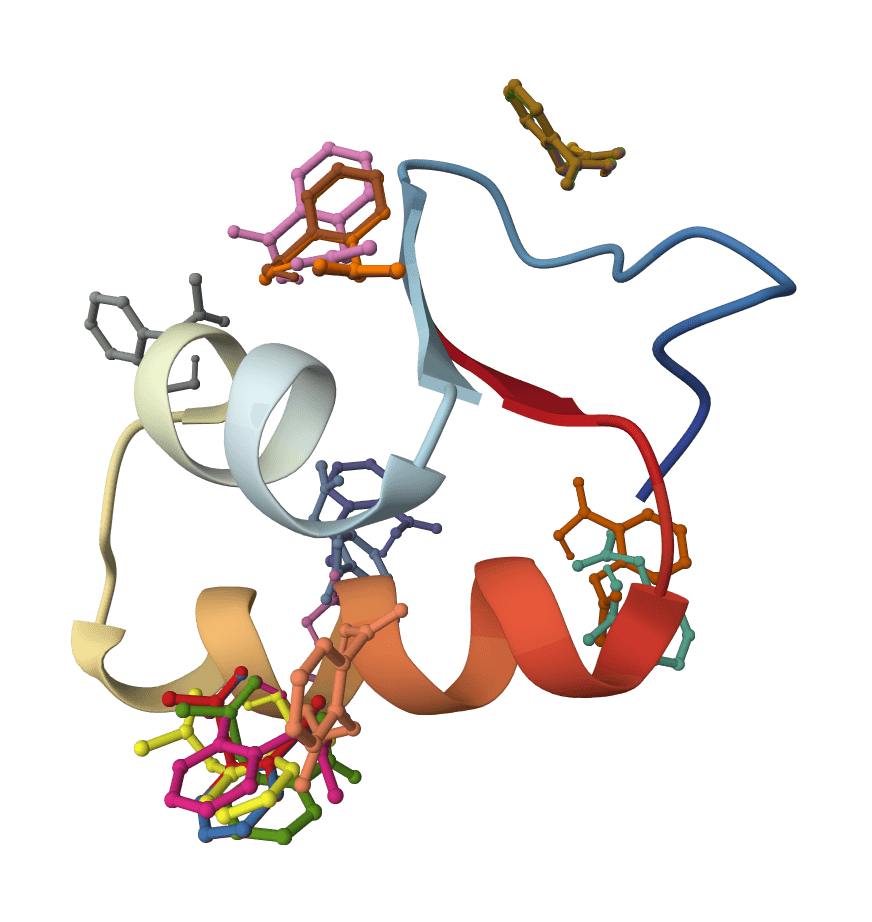
AF2BIND predicts ligand-binding residues from a protein structure using AlphaFold2 pair representations and a 20-residue bait sequence.
eToxPred is a machine learning tool for predicting the toxicity and synthetic accessibility of small molecules from their chemical structures. Developed at Louisiana State University by Limeng Pu, Michal Brylinski, and colleagues, eToxPred filters out potentially toxic or difficult-to-synthesize compounds early in the drug discovery process.
The tool provides two complementary scores:
Together, these scores help prioritize which drug candidates are worth pursuing.
As such, we recommend using eToxPred for the following screening applications:
ProteinIQ provides a web-based interface for running eToxPred without command-line installation or Python environment configuration. Enter SMILES strings, adjust optional settings, and receive toxicity and synthetic accessibility predictions.
| Input | Description |
|---|---|
Molecule | SMILES strings for compounds to analyze. Enter one SMILES per line, or use tab-separated format with compound names: aspirin CC(=O)Oc1ccccc1C(=O)O. Supports file upload (.smi, .smiles, .txt, .csv) or PubChem batch fetching. |
The output is a spreadsheet with toxicity and synthetic accessibility predictions for each compound.
| Column | Description |
|---|---|
Compound ID | Name provided in input or auto-generated identifier (Compound_1, Compound_2, etc.). |
SMILES | The input SMILES string for reference. |
Toxicity Score | Probability of toxicity (0–1). Higher values indicate greater toxicity risk. |
SA Score | Synthetic accessibility score (1–10, normalized to 0–1 in output). Lower values indicate easier synthesis. |
The Tox-score represents the probability that a compound exhibits general toxicity based on structural similarity to known toxic and non-toxic compounds.
| Tox-score | Risk level | Recommendation |
|---|---|---|
| 0.0–0.3 | Low | Proceed with standard testing |
| 0.3–0.5 | Moderate | Investigate structural features |
| 0.5–0.7 | Elevated | Consider structural modifications |
| 0.7–1.0 | High | Likely requires redesign |
The optimal discrimination threshold is 0.58, which most effectively separates toxic from non-toxic compounds in validation studies. FDA-approved drugs have a median Tox-score of approximately 0.34, while known toxins from the T3DB database typically score above 0.6.
The SA score estimates synthetic difficulty, where lower values indicate compounds that would be easier to synthesize.
| SA score | Difficulty | Synthesis outlook |
|---|---|---|
| 0.0–0.2 | Very easy | Standard organic synthesis |
| 0.2–0.4 | Easy | Routine synthesis, few steps |
| 0.4–0.6 | Moderate | Multi-step synthesis required |
| 0.6–0.8 | Difficult | Challenging, specialist skills needed |
| 0.8–1.0 | Very difficult | May require novel methodology |
Drug-like molecules typically have SA scores between 0.2 and 0.5. Scores above 0.6 suggest the compound may be impractical for lead optimization due to synthetic challenges.
eToxPred combines two independent prediction models: an Extremely Randomized Trees (Extra Trees) classifier for toxicity prediction and a Deep Belief Network for synthetic accessibility scoring.
The toxicity model was trained on 4,550 compounds: 1,515 FDA-approved drugs representing the non-toxic class and 3,035 compounds from TOXNET representing the toxic class. Independent validation used 3,682 compounds from KEGG-Drug (non-toxic) and 1,283 compounds from T3DB (toxic).
Each molecule is converted to a 1024-bit Daylight fingerprint using Open Babel. These binary fingerprints encode the presence or absence of structural fragments, capturing the chemical features relevant to toxicity.
The Extra Trees algorithm builds an ensemble of 500 decision trees, each trained on random subsets of fingerprint features. Key hyperparameters:
The ensemble votes on classification, with the final Tox-score representing the proportion of trees predicting toxicity. This approach handles noisy biological data well and resists overfitting.
The SA score combines historical synthetic knowledge with complexity penalties. A Deep Belief Network with architecture 1024→512→128→32 nodes was trained to predict SA scores, achieving a Pearson correlation of 0.89 with experimental values.
The fragment score compares molecular substructures against fragments frequently found in known synthesized compounds. Common fragments score higher (easier to make); unusual fragments score lower.
The complexity penalty accounts for structural features that complicate synthesis:
eToxPred was validated on independent test sets not used during training.
| Metric | Value |
|---|---|
| Accuracy | 72.1% |
| Sensitivity (true positive rate) | 63.1% |
| Specificity | 75.2% |
| Matthews Correlation Coefficient | 0.35 |
| ROC AUC | 0.82 |
The model was also evaluated on datasets for specific toxicity types:
| Endpoint | AUC | Accuracy |
|---|---|---|
| Acute oral toxicity | 0.80 | 85.4% |
| Cardiotoxicity | 0.80 | 79.8% |
| Endocrine disruption | 0.75 | 74.4% |
| Carcinogenicity | 0.72 | 72.2% |
The SA score model achieves a mean squared error of approximately 4% when compared to reference SA scores.
Several tools on ProteinIQ address overlapping aspects of compound evaluation:
eToxPred provides general toxicity screening with synthetic accessibility in a single analysis. The machine learning model captures patterns across diverse toxic compounds but does not distinguish between specific toxicity mechanisms.
ADMET-AI uses graph neural networks to predict 41 specific ADMET endpoints, including hERG inhibition (cardiotoxicity), hepatotoxicity, CYP interactions, and plasma protein binding. For endpoint-specific toxicity predictions, ADMET-AI offers more detailed information.
Toxicity Prediction uses rule-based structural alerts (PAINS, Brenk filters) rather than machine learning. This approach identifies specific problematic substructures like reactive groups or known interference patterns. The two approaches are complementary—eToxPred captures general toxicity patterns while structural alerts identify specific problematic features.
Lipinski's Rule of 5 evaluates oral bioavailability potential using simple physicochemical rules (molecular weight, LogP, hydrogen bond donors/acceptors). This rule-based approach is interpretable but does not predict toxicity.
QEPPi scores drug-likeness specifically for protein-protein interaction inhibitors, which require different physicochemical properties than conventional drugs.
A typical drug discovery screening workflow incorporating eToxPred:
Aspirin (acetylsalicylic acid): CC(=O)Oc1ccccc1C(=O)O
Caffeine: Cn1cnc2c1c(=O)n(c(=O)n2C)C
These scores align with expectations—both are well-tolerated, easily synthesized compounds that have been safely used for decades.