Related tools
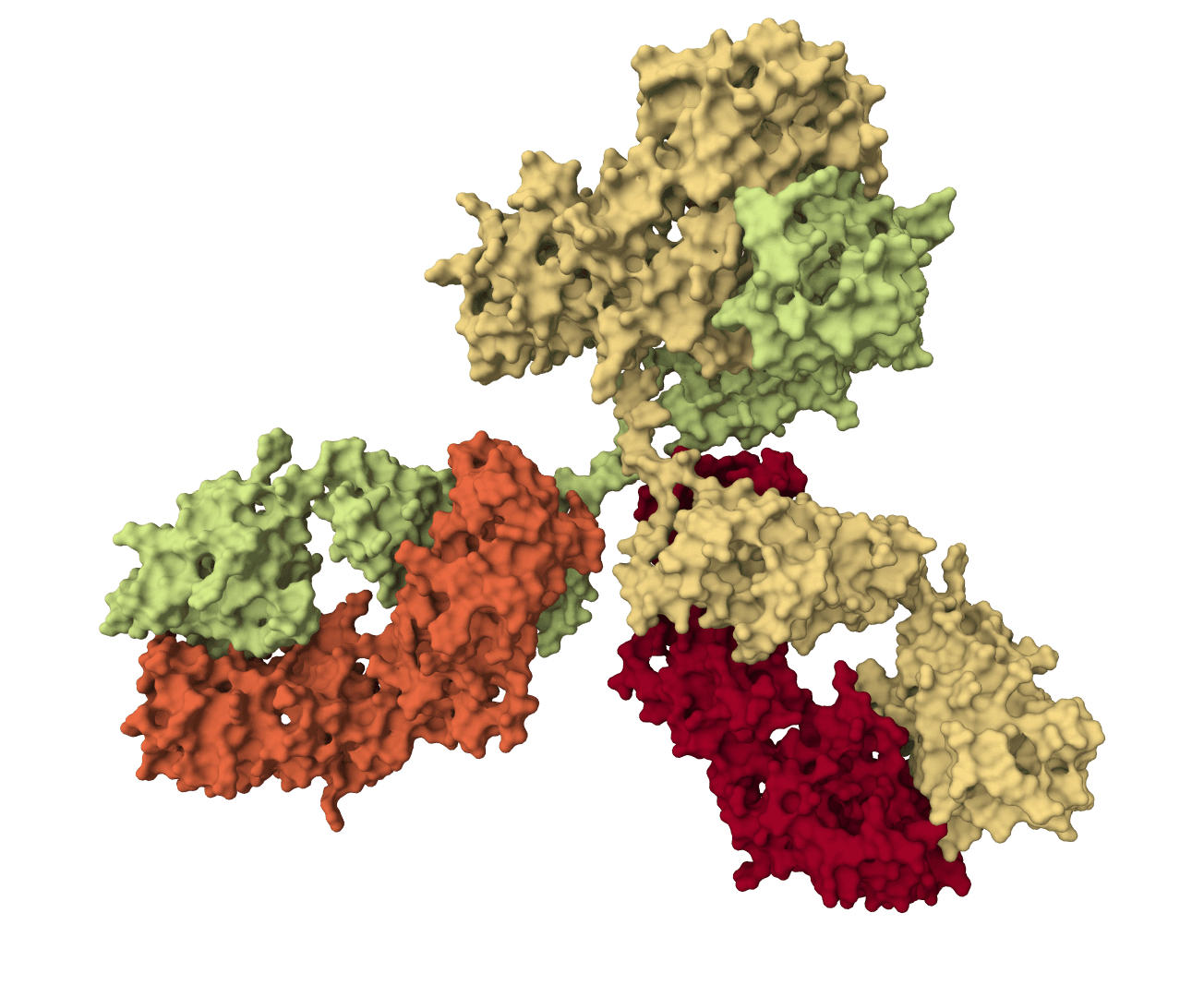
RFantibody
Structure-based de novo antibody and nanobody design pipeline combining antibody-tuned RFdiffusion, ProteinMPNN sequence design, and antibody-tuned RoseTTAFold2 filtering.
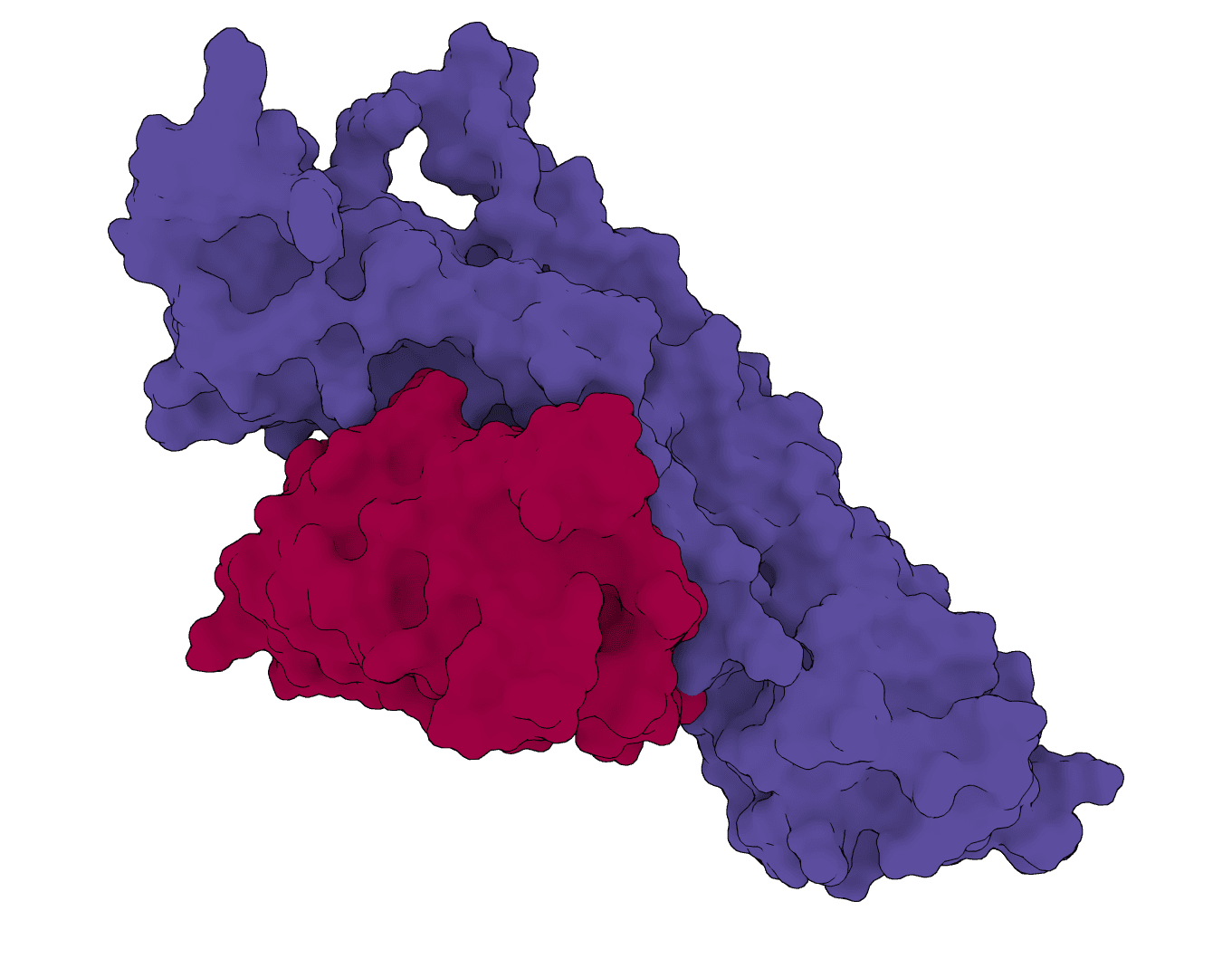
DiffAb
AI-powered antibody CDR design using equivariant diffusion models. Generates optimized complementarity-determining region (CDR) sequences and structures for antibodies targeting specific antigens. Supports single CDR, multi-CDR co-design, and fixed-backbone sequence design modes.
Genie 3
Generate protein structures and scaffolds with Genie 3, an all-atom SE(3)-equivariant diffusion model. Genie 3 supports unconditional protein generation, motif scaffolding, and hotspot-targeted binder design.
BioPhi
Antibody humanization and humanness evaluation platform from Merck. Sapiens mode uses deep learning trained on the Observed Antibody Space (OAS) to humanize antibody sequences, while OASis mode evaluates humanness using 9-mer peptide search against human antibody databases.
BoltzGen
BoltzGen is a state-of-the-art AI model for designing protein and peptide binders against any biomolecular target. Using generative diffusion models, it creates novel binders (proteins, peptides, nanobodies) with nanomolar-level binding affinity.
EvoDiff
EvoDiff is a diffusion-based protein sequence generation framework from Microsoft Research. ProteinIQ currently runs the EvoDiff-Seq OA_DM_38M model for unconditional protein generation, motif scaffolding, and user-sequence inpainting.
ODesign
All-atom generative AI for designing protein binders. Specify target binding sites and generate diverse binding proteins with fine-grained control over interaction parameters.
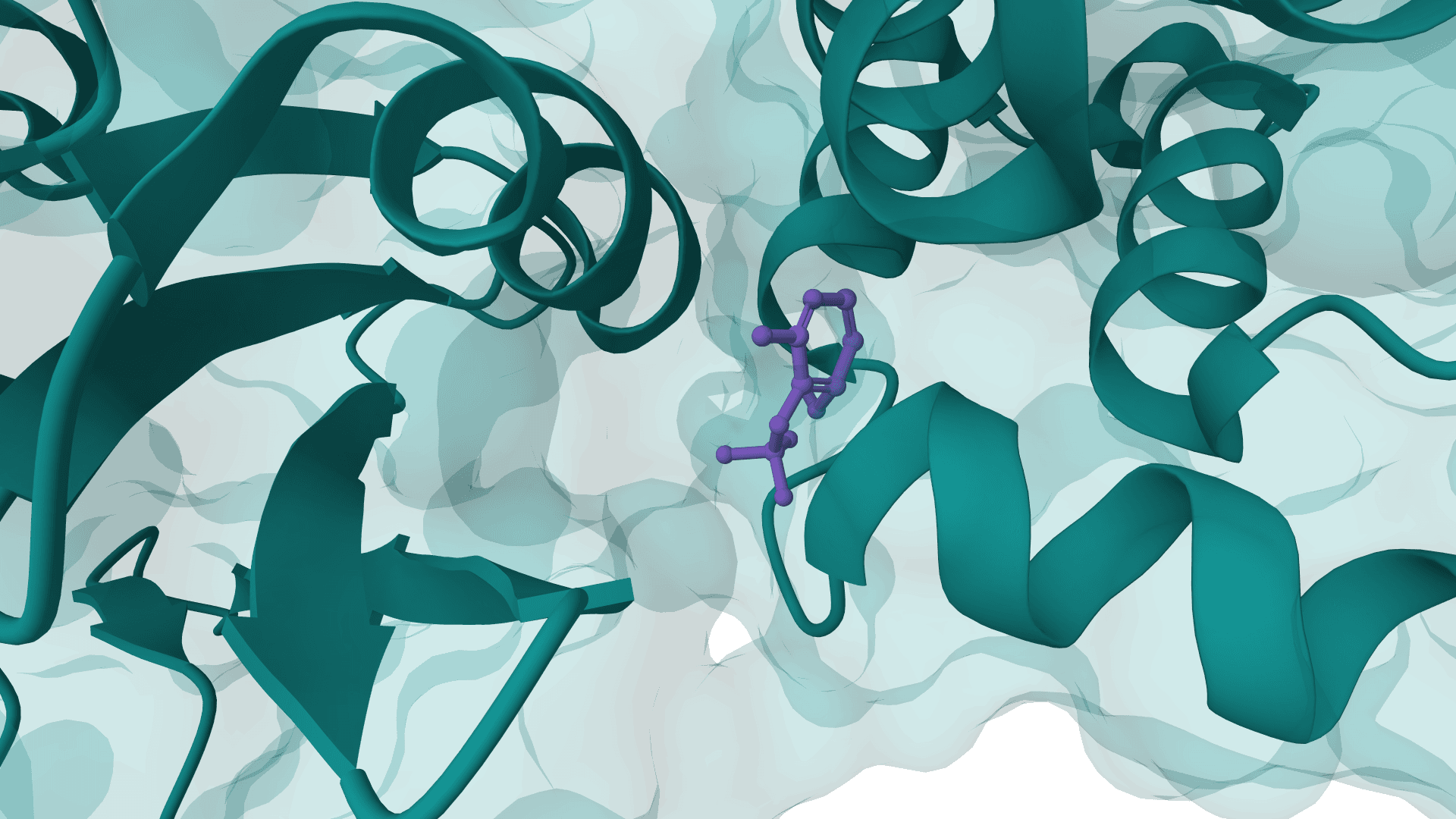
PocketFlow
PocketFlow is a structure-based molecular generative model that designs novel drug-like molecules within protein binding pockets. It uses autoregressive flow modeling with chemical knowledge to generate 100% chemically valid, highly drug-like compounds.
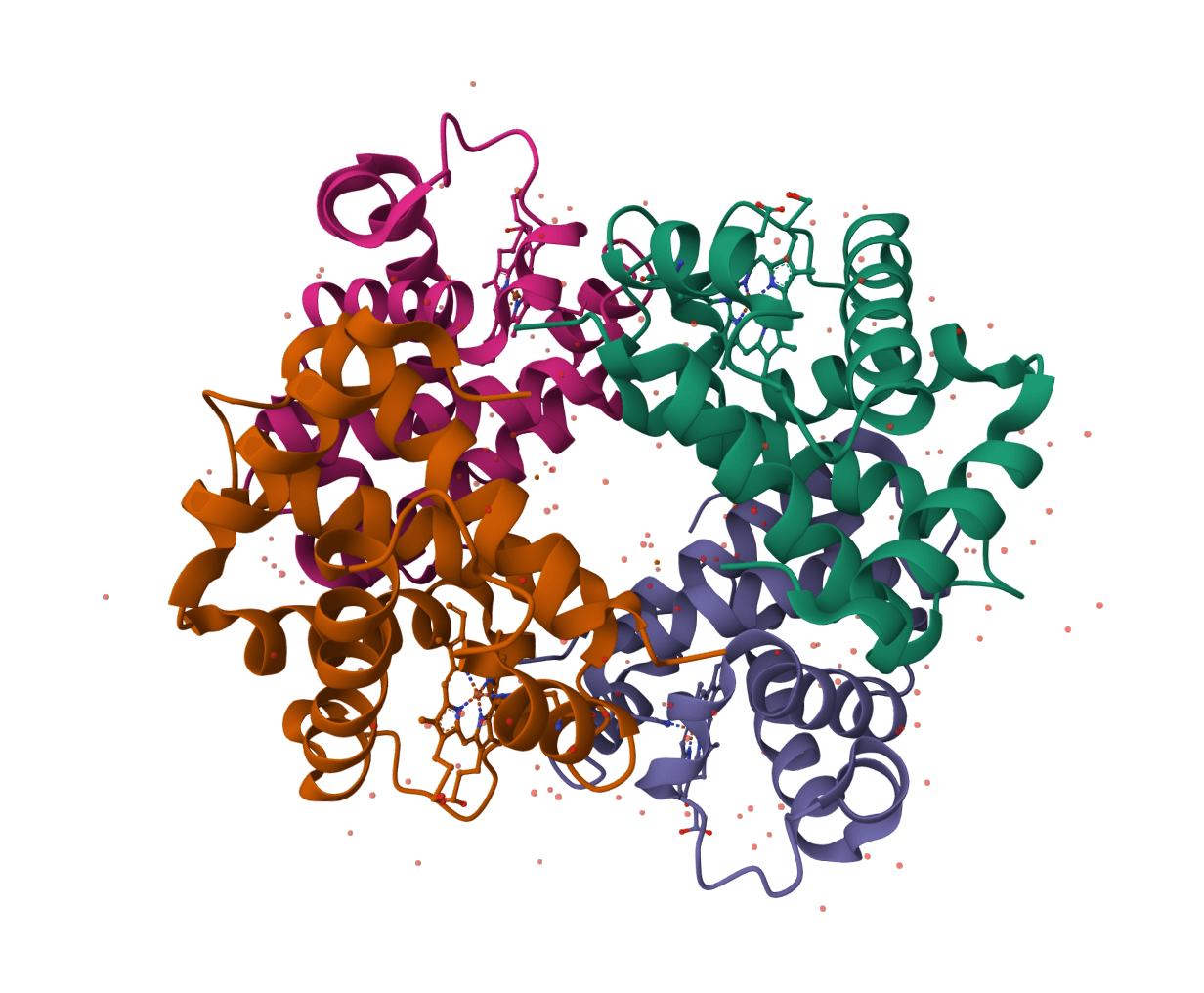
PocketXMol
PocketXMol is a pocket-interacting generative foundation model for docking, small-molecule design, and peptide design in protein binding pockets.
Proteina-Complexa
Design protein binders against a target structure with NVIDIA BioNeMo's Proteina-Complexa generative pipeline.