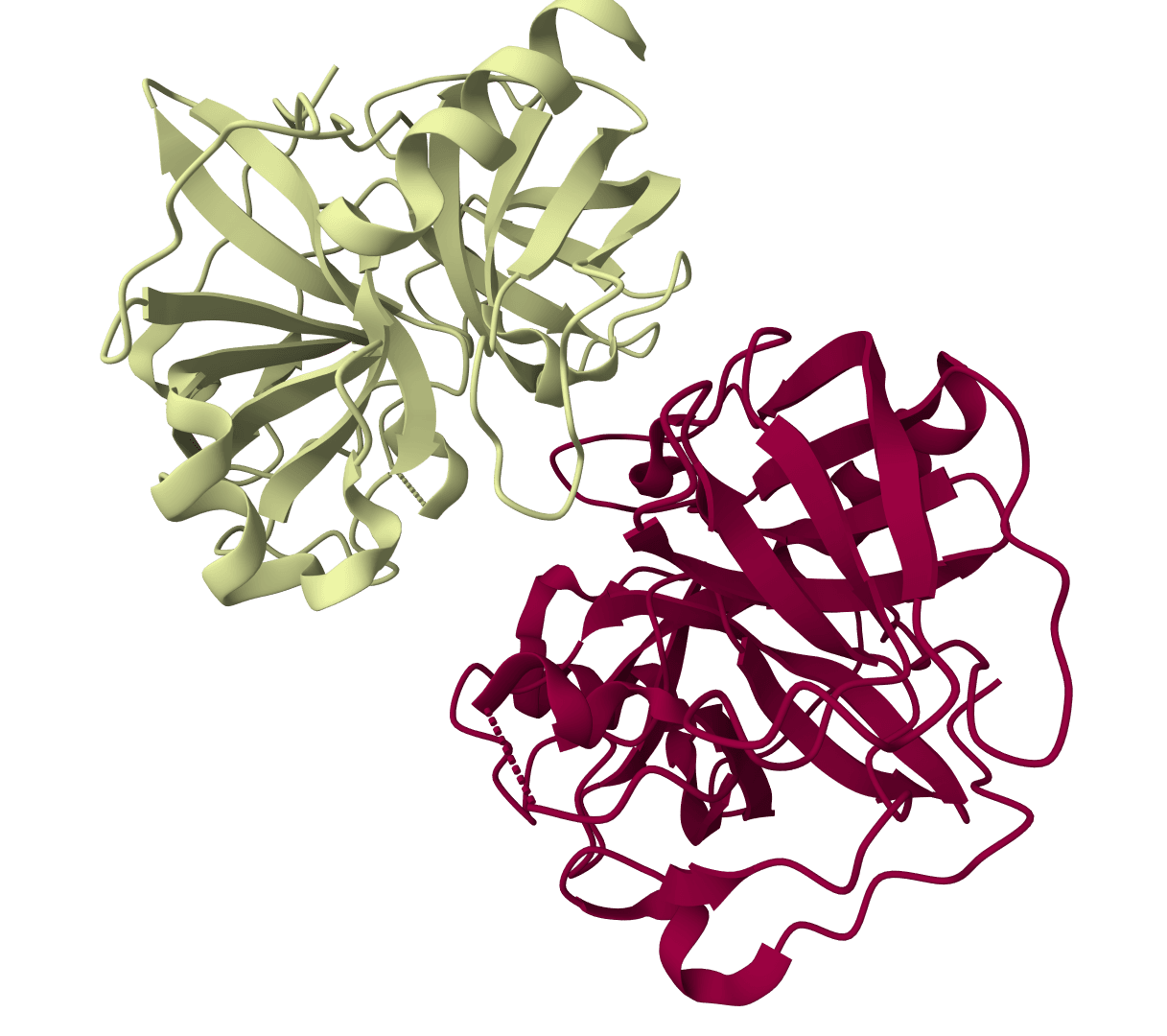
What is AF-Cluster?
AF-Cluster is a method for predicting multiple protein conformations by clustering a multiple sequence alignment (MSA) before running AlphaFold2. Standard AlphaFold2 predictions converge on a single dominant structure, even for proteins that adopt two or more biologically relevant folds. AF-Cluster addresses this by splitting the MSA into sequence subgroups using the DBSCAN density-based clustering algorithm, then generating separate AlphaFold2 predictions from each cluster.
The approach was developed by Hannah Wayment-Steele, Sergey Ovchinnikov, Lucy Colwell, Dorothee Kern, and colleagues at Brandeis University, and published in Nature in 2023. The authors validated the method on metamorphic proteins, including the cyanobacterial clock protein KaiB, where AF-Cluster correctly predicted both the ground-state and fold-switched conformations. NMR spectroscopy confirmed that a KaiB variant predicted by AF-Cluster was indeed stabilized in the opposite fold.
How does AF-Cluster work?
Proteins evolve under selective pressure to maintain function, and function often requires switching between conformational states. Homologous sequences in an MSA may carry co-evolutionary signals for different conformations. When the full MSA is fed to AlphaFold2, these conflicting signals average out and the prediction collapses onto a single state.
AF-Cluster separates these signals by clustering the MSA:
- Gap filtering: Sequences with excessive gaps relative to the query are removed to reduce noise.
- Distance calculation: Pairwise edit distances are computed between all sequences in the alignment.
- DBSCAN clustering: The algorithm identifies dense regions in sequence space. Each cluster must contain at least
min_samplessequences, and sequences withinepsilondistance of a core point are assigned to the same cluster. Sequences that do not fall within any dense region are labeled as noise. - Epsilon optimization: When epsilon is not specified, AF-Cluster scans a range of values and selects the one that maximizes the number of identified clusters. Too small an epsilon marks most sequences as noise; too large an epsilon merges distinct clusters together.
- Consensus generation: A consensus sequence is derived from each cluster, representing the dominant residue at each position within that subgroup.
Each cluster's alignment can then be used as input to AlphaFold2 independently, producing structure predictions that may capture different conformational states.
How to use AF-Cluster online
ProteinIQ runs AF-Cluster directly in the browser, handling the clustering pipeline on cloud infrastructure with no software installation needed.
Input
| Input | Description |
|---|---|
Multiple Sequence Alignment | An MSA in FASTA or A3M format. The first sequence is treated as the query. Minimum 10 sequences required. Upload a file (up to 100 MB) or paste directly. |
MSAs can be generated from tools like Clustal Omega or MAFFT, or obtained from databases such as UniRef or ColabFold search.
Settings
| Setting | Description |
|---|---|
Min samples per cluster | Minimum number of sequences required to form a DBSCAN cluster (2–20, default 3). Higher values produce fewer, more populated clusters. |
Gap fraction cutoff | Remove sequences with more than this fraction of gaps relative to the query (0–1, default 0.25). Lower values enforce stricter filtering. |
DBSCAN epsilon | Maximum distance for points to be grouped into a cluster (0–10, default 0 for automatic). When set to 0, AF-Cluster scans a range of epsilon values and selects the one yielding the most clusters. |
Visualization
| Setting | Description |
|---|---|
Generate PCA plot | Project clustered sequences onto their first two principal components. Useful for seeing how clusters separate in sequence space. |
Generate t-SNE plot | Non-linear embedding of sequence distances. Can reveal cluster structure that PCA misses, but is more computationally intensive and results vary between runs. |
Output
AF-Cluster produces several files:
- Cluster alignments: Separate A3M files for each identified cluster, ready for structure prediction with AlphaFold2 or other folding tools.
- Clustering assignments: A table mapping each input sequence to its assigned cluster (or -1 for noise/unassigned sequences).
- Cluster metadata: Summary statistics for each cluster, including size and composition.
- Visualizations: PCA and/or t-SNE plots if enabled, showing how sequences distribute across clusters.
Applications
AF-Cluster is most valuable for proteins suspected of adopting multiple folds:
- Metamorphic proteins: Proteins like KaiB, lymphotactin, and RfaH that switch between entirely different folds. Standard AlphaFold2 typically predicts only the dominant state.
- Conformational ensembles: Enzymes or receptors with open/closed states, active/inactive forms, or ligand-induced rearrangements.
- Protein family surveys: Screening an entire protein family for members that may adopt alternative folds, even when fold-switching has not been experimentally observed.
- Mutation design: Identifying residue positions where mutations might shift the conformational equilibrium. The original study designed three mutations predicted to flip KaiB into its fold-switched state, confirmed by NMR.
Limitations
- Depends on MSA quality: The method requires an MSA with sufficient sequence diversity. Small or shallow alignments may not contain enough signal for meaningful clustering.
- No guarantee of biological relevance: Not every cluster corresponds to a true conformational state. Some clusters may reflect phylogenetic divergence rather than structural differences.
- Single-domain focus: AF-Cluster was developed and validated primarily on single-domain proteins and metamorphic switches. Multi-domain or disordered proteins may not benefit from this approach.
- Sensitivity to parameters: The choice of epsilon and minimum samples affects which clusters emerge. Automatic epsilon selection works well in many cases but is not infallible.
- Downstream prediction required: AF-Cluster prepares MSA subsets but does not itself predict structures. A separate folding step with AlphaFold2 or a similar tool is needed to generate 3D models from each cluster.
Related tools

RAxML-NG
Perform maximum-likelihood phylogenetic tree inference with RAxML-NG for aligned protein or DNA sequences. Supports ML search, bootstrap analysis, and native automatic model-family selection.
DR-BERT
DR-BERT is a compact protein language model that predicts intrinsically disordered regions (IDRs) in proteins. It outputs per-residue disorder probability scores (0–1) from amino acid sequences, enabling fast and accurate annotation of disordered regions without structural data.
AbLang
Restore missing residues in antibody sequences using a language model trained on the Observed Antibody Space (OAS) database. Achieves better restoration than IMGT germlines or ESM-1b while being 7x faster.
AbLang-2
Antibody-specific language model for predicting non-germline residues (NGL) in antibody sequences. AbLang-2 addresses germline bias in existing antibody language models by focusing on somatic hypermutation patterns, enabling more accurate prediction of amino acid likelihoods and generation of context-aware embeddings for antibody sequences.
Aggrescan3D
Faithful static-mode Aggrescan3D tool for per-residue aggregation propensity analysis from a single protein structure.
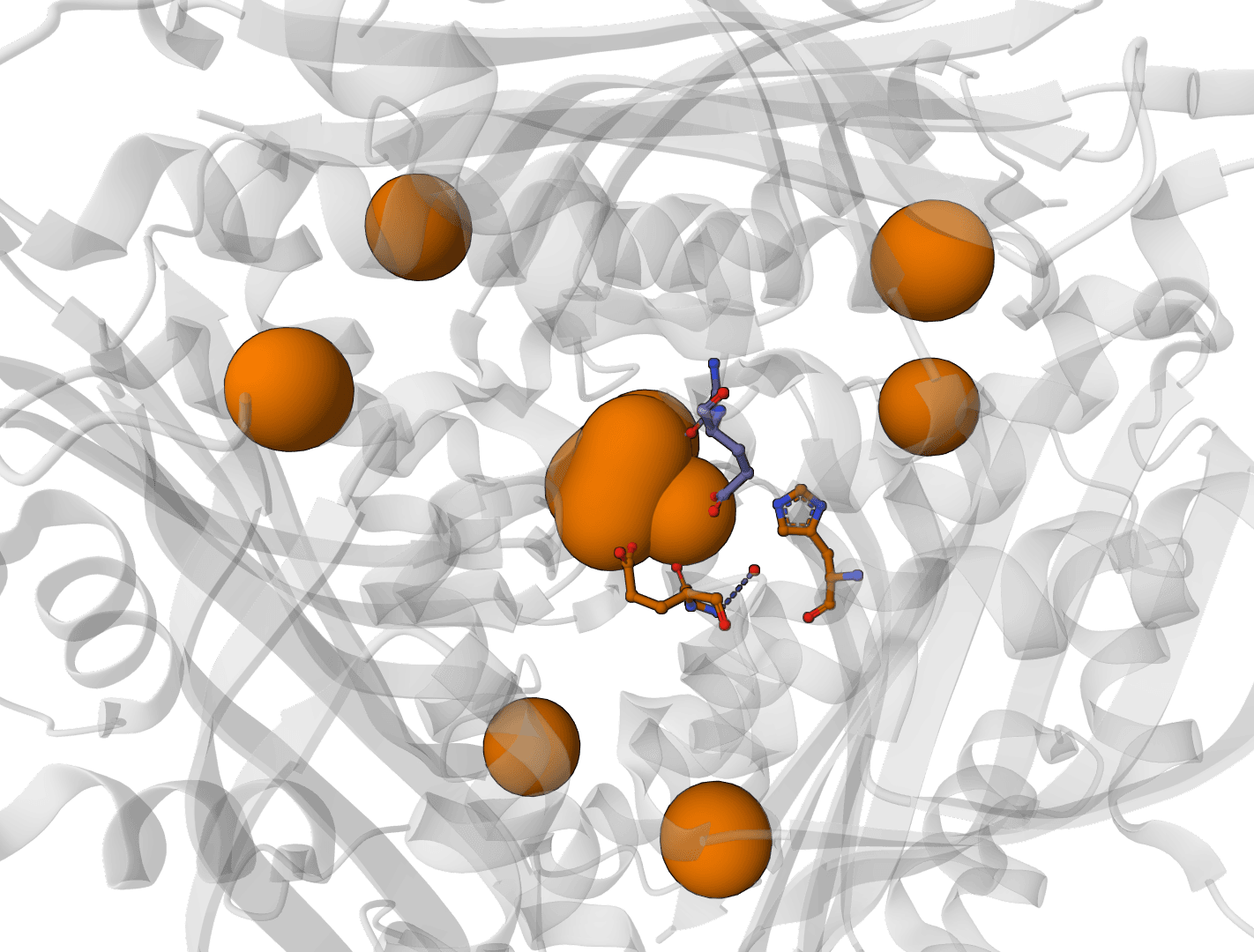
AllMetal3D
Predict metal and water binding sites in protein structures using 3D convolutional neural networks (AllMetal3D + Water3D).
CANYA
Predict protein aggregation nucleation propensity from amino acid sequences using the Lehner Lab CANYA neural network.
DeepEMhancer
DeepEMhancer is a deep learning-based post-processing tool for cryo-EM maps. It performs automatic sharpening, masking, and denoising in a single step without requiring an atomic model. Supports half-map inputs for improved local mask estimation.
ESM-2
ESM-2 is a 650M parameter protein language model from Meta AI trained on 250M protein sequences. Generate rich sequence representations for downstream tasks like structure prediction, function annotation, and variant effect prediction.
ESM-C
ESM-C generates protein sequence representations and optional masked-token logits using Biohub protein language models. It supports the 300M, 600M, and 6B model variants for embedding extraction from canonical amino acid sequences.